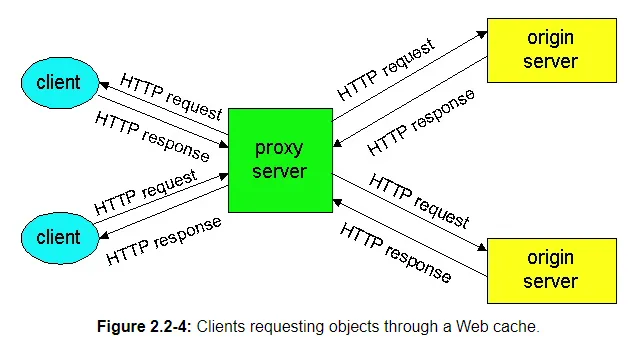
A Web cache – also called a proxy server – is a network entity that satisfies HTTP requests on the behalf of a client. The Web cache has its own disk storage, and keeps in this storage copies of recently requested objects. As shown in Figure 2.2-4, users configure their browsers so that all of their HTTP requests are first directed to the Web cache. (This is a straightforward procedure with Microsoft and Netscape browsers.) Once a browser is configured, each browser request for an object is first directed to the Web cache. As an example, suppose a browser is requesting the object http://www.someschool.edu/campus.webp.
Note that a cache is both a server and a client at the same time. When it receives requests from and sends responses to a browser, it is a server. When it sends requests to and receives responses from an origin server it is a client.
So why bother with a Web cache? What advantages does it have? Web caches are enjoying wide-scale deployment in the Internet for at least three reasons. First, a Web cache can substantially reduce the response time for a client request, particularly if the bottleneck bandwidth between the client and the origin server is much less than the bottleneck bandwidth between the client and the cache. If there is a high-speed connection between the client and the cache, as there often is, and if the cache has the requested object, then the cache will be able to rapidly deliver the object to the client. Second, as we will soon illustrate with an example, Web caches can substantially reduce traffic on an institution's access link to the Internet. By reducing traffic, the institution (e.g., a company or a university) does not have to upgrade bandwidth as quickly, thereby reducing costs. Furthermore, Web caches can substantially reduce Web traffic in the Internet as a whole, thereby improving performance for all applications. In 1998, over 75% of Internet traffic was Web traffic, so a significant reduction in Web traffic can translate into a significant improvement in Internet performance [Claffy 1998]. Third, an Internet dense with Web caches – e.g., at institutional, regional and national levels – provides an infrastructure for rapid distribution of content, even for content providers who run their sites on low-speed servers behind low-speed access links. If such a "resouce-poor" content provider suddenly has popular content to distribute, this popular content will quickly be copied into the Internet caches, and high user demand will be satisfied.
To gain a deeper understanding of the benefits of caches, let us consider an example in the context of Figure 2.2-5. In this figure, there are two networks – the institutional network and the Internet. The institutional network is a high-speed LAN. A router in the institutional network and a router in the Internet are connected by a 1.5 Mbps link. The institutional network consists of a high-speed LAN which is connected to the Internet through a 1.5 Mbps access link. The origin servers are attached to the Internet, but located all over the globe. Suppose that the average object size is 100 Kbits and that the average request rate from the institution's browsers to the origin servers is 15 requests per second. Also suppose that amount of time it takes from when the router on the Internet side of the access link in Figure 2.2-5 forwards an HTTP request (within an IP datagram) until it receives the IP datagram (typically, many IP datagrams) containing the corresponding response is two seconds on average. Informally, we refer to this last delay as the "Internet delay".
The total response time – that is the time from when a browser requests an object until the browser receives the object – is the sum of the LAN delay, the access delay (i.e., the delay between the two routers) and the Internet delay. Let us now do a very crude calculation to estimate this delay. The traffic intensity on the LAN (see Section 1.6) is
(15 requests/sec) × (100 Kbits/request)/(10 Mbps) = .15
whereas the traffic intensity on access link (from Internet router to institution router) is
(15 requests/sec) × (100 Kbits/request)/(1.5 Mbps) = 1
A traffic intensity of .15 on a LAN typically results in at most tens of milliseconds of delay; hence, we can neglect the LAN delay. However, as discussed in Section 1.6, as the traffic intensity approaches 1 (as is the case of the access link in Figure 2.2-5), the delay on a link becomes very large and grows without bound. Thus, the average response time to satisfy requests is going to be on the order of minutes, if not more, which is unacceptable for the institution's users. Clearly something must be done.
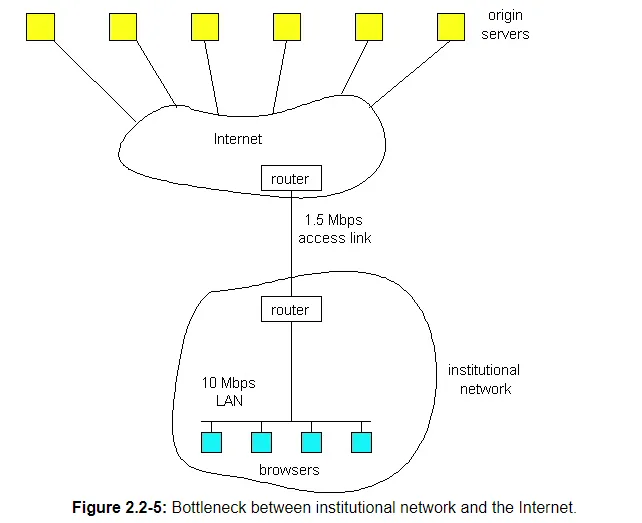
One possible solution is to increase the access rate from 1.5 Mbps to, say, 10 Mbps. This will lower the traffic intensity on the access link to .15, which translates to negligible delays between the two routers. In this case, the total response response time will roughly be 2 seconds, that is, the Internet delay. But this solution also means that the institution must upgrade its access link from 1.5 Mbps to 10 Mbps, which can be very costly.
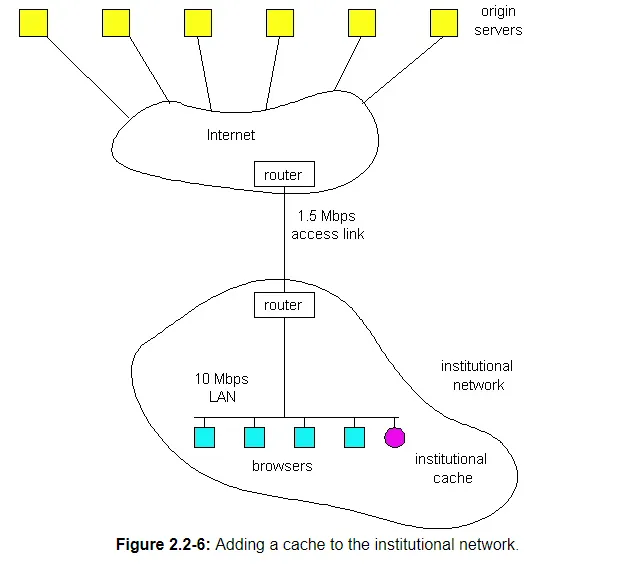
Now consider the alternative solution of not upgrading the access link but instead installing a Web cache in the institutional network. This solution is illustrated in Figure 2.2-6. Hit rates – the fraction of requests that are satisfied by a cache – typically range from .2 to .7 in practice. For illustrative purposes, let us suppose that the cache provides a hit rate of .4 for this institution. Because the clients and the cache are connected to the same high-speed LAN, 40% of the requests will be satisfied almost immediately, say within 10 milliseconds, by the cache. Nevertheless, the remaining 60% of the requests still need to be satisfied by the origin servers. But with only 60% of the requested objects passing through the access link, the traffic intensity on the access link is reduced from 1.0 to .6. Typically a traffic intensity less than .8 corresponds to a small delay, say tens of milliseconds, on a 1.5 Mbps link, which is negligible compared with the 2 second Internet delay. Given these considerations, average delay therefore is
.4 × (0.010 seconds) + .6 × (2.01 seconds)
which is just slightly larger than 2.1 seconds. Thus, this second solution provides an even lower response time then the first solution, and it doesn't require the institution to upgrade its access rate. The institution does, of course, have to purchase and install a Web cache. But this cost is low – many caches use public-domain software that run on inexpensive servers and PCs.
Multiple Web caches, located at different places in the Internet, can cooperate and improve overall performance. For example, an institutional cache can be configured to send itsHTTP requests to a cache in a backbone ISP at the national level. In this case, when the institutional cache does not have the requested object in its storage, it forwards the HTTPrequest to the national cache. The national cache then retrieves the object from its own storage or, if the object is not in storage, from the origin server. The national cache then sends the object (within an HTTP response message) to the institutional cache, which in turn forwards the object to the requesting browser. Whenever an object passes through a cache (institutional or national), the cache leaves a copy in its local storage. The advantage of passing through a higher-level cache, such as a national cache, is that it has a larger user population and therefore higher hit rates.
An example of cooperative caching system is the NLANR caching system, which consists of a number of backbone caches in the US providing service to institutional and regional caches from all over the globe [NLANR]. The NLANR caching hierarchy is shown in Figure 2.2-7 [Huffaker 1998]. The caches obtain objects from each other using a combination of HTTP and ICP (Internet Caching Protocol). ICP is an application-layer protocol that allows one cache to quickly ask another cache if it has a given document [RFC 2186]; a cache can then use HTTP to retrieve the object from the other cache. ICP is used extensively in many cooperative caching systems, and is fully supported by Squid, a popular public-domain software for Web caching [Squid]. If you are interested in learning more about ICP, you are encouraged to see [Luotonen 1998] [Ross 1998] and the ICP RFC [RFC 2186].
An alternative form of cooperative caching involves clusters of caches, often co-located on the same LAN. A single cache is often replaced with a cluster of caches when the single cache is not sufficient to handle the traffic or provide sufficient storage capacity. Although cache clustering is a natural way to scale as traffic increases, they introduce a new problem: When a browser wants to request a particular object, to which cache in the cache cluster should it send the request? This problem can be elegantly solved using hash routing (If you are not familiar with hash functions, you can read about them in Chapter 7.) In the simplest form of hash routing, the browser hashes the URL, and depending on the result of the hash, the browser directs its request message to one of the caches in the cluster. By having all the browsers use the same hash function, an object will never be present in more than one cache in the cluster, and if the object is indeed in the cache cluster, the browser will always direct its request to the correct cache. Hash routing is the essence of the Cache Array Routing Protocol (CARP). If you are interested in learning more about hash routing or CARP, see [Valloppillil 1997], [Luotonen 1998], [Ross 1998] and [Ross 1997].
Web caching is a rich and complex subject; over two thirds (40 pages) of the HTTP/1.1 RFC is devoted to Web caching [RFC 2068]! Web caching has also enjoyed extensive research and product development in recent years. Furthermore, caches are now being built to handle streaming audio and video. Caches will likely play an important role as the Internet begins to provide an infrastructure for the large-scale, on-demand distribution of music, television shows and movies in the Internet.