Back to the Future: Waves of Legal Scholarship on Artificial Intelligence
In the past years, legal scholarship on technology matters has become ubiquitous. Topics such as self-driving cars, predictive policing or discriminatory profiling are only a few examples of trending legal research, mirroring similar academic developments in other scientific disciplines – especially in computer science research. Interestingly, and perhaps not surprisingly, the same research questions asked in relation to artificial intelligence have been posed in earlier research decades ago, as 2019 is not the first year when the academic community asks itself about the consequences of autonomous decision-making. Yet since it is getting more and more difficult to have an overview of existing work on the subject, this may lead to repetitive research.
Our research looks at this literature inflation by analysing a corpus of 3931 academic journal articles obtained from HeinOnline referencing the topic of artificial intelligence (the Corpus). Our approach is two-fold:
First, in a book chapter currently under production, (forthcoming in Sofia Ranchordás and Yaniv Roznai, Time, Law and Change: An Interdisciplinary Study, Hart Publishing 2020), we describe the Corpus, including the methodology used in obtaining it and the characteristics of the publications therein, with the goal of visualizing it using descriptive statistics, and briefly explaining the statistical model (Latent Dirichlet Allocation Topic Modelling - LDA) to be used for further analysis.
Second, as ongoing research (also with Constanta Rosca), we are currently deploying the LDA topic modelling method to extract the topics that characterize the Corpus.
Mapping legal research on AI
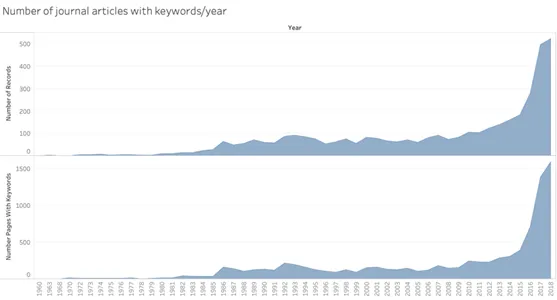
The Corpus includes a total of 3931 journal articles obtained from HeinOnline as a result of a Data and Text Mining Agreement. Absent a centralised, comprehensive, open access repository for international legal scholarship, we focused on a commercially-available database. We chose HeinOnline as a leading international databases on legal materials, containing over 170 million pages of literature and indexing over 2700 law journals. Figure 1 shows an increase in the popularity of artificial intelligence in the Corpus, especially between 2016 and 2018.
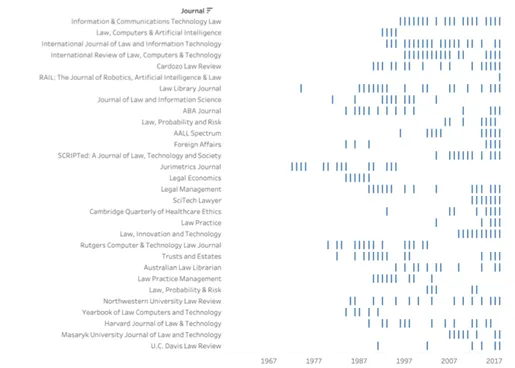
A detailed overview of the number of publications on artificial intelligence per journal – along with the complete list of the 1113 journals included in the analysis – are available on record and may be requested electronically until a project website is set up (example below).
The need for automated research
Part two of our research project focuses on applying quantitative data analysis methods to the Corpus, particularly topic modelling. As mentioned above, completing a qualitative systematic literature review of over 3900 papers is a quasi-impossible task to achieve for a legal scholar using traditional methods of legal inquiry. Yet in the absence of an overall image of existing literature, it is difficult to understand macro trends in a body of legal research. In the field of empirical legal research, text analysis has so far been done with the help of human coding, a time-consuming and sometimes inaccurate method, especially when it needs to be applied to a high volume and high variety of unstructured text. Topic models are statistical algorithms that have the potential to address such shortcomings, as they are used to ‘summarize, explore and index large collections of text documents’. Topic modelling algorithms such as Latent Dirichlet Allocation are also called ‘generative models’, since they are based on the assumption that any document is generated by sampling words given specific topic probabilities (and actually the model attempts to learn these probabilities). Topic modelling has been widely used in computer science, but is increasingly used in the emerging field of computational social sciences, with the goal of augmenting social science analysis.
Reflecting on legal research and AI
To reflect on where legal research on AI is heading, there are four main points we address in our research.
First, on the basis of a preliminary (non-systematic) qualitative overview, it seems there is a trend for legal research on artificial intelligence to generally become less specialised. In earlier decades, only a handful of researchers were interested in the topic, driven by the same appreciation of formal reasoning and the goal of applying artificial intelligence to very practical questions of legal information retrieval.
Secondly, research questions appear to follow a cycle. For instance, while the field of robotics may have seen considerable technological progress since the mid 80s, the matrix of legal questions – as well as answers – which may be given in response to the challenge of integrating robots in society is rather finite. From this perspective, legal scholars must very carefully consider the added value of contributing to topics where thorough research unveils that most – if not all – of these permutations have already been addressed.
Thirdly, legal research ought to include more meta-studies and literature reviews. Legal issues arising out of artificial intelligence are becoming more and more technically and societally sophisticated, yet given the volume of information, it takes a long time to catch up and stay up to date with all relevant sources.
Lastly, the research community could also benefit from reconsidering publication incentives. Legal research is ideally about furthering the boundaries of knowledge, and contributing to either the theory or practice of law through this knowledge. What hypes in legal research reveal is that sometimes, published legal research does not fulfil this goal. Instead, scholars may sometimes choose to focus on topics that are popular because they may increase their reputation or their funding chances.