The Machine Learning Life Cycle – 5 Challenges for DevOps
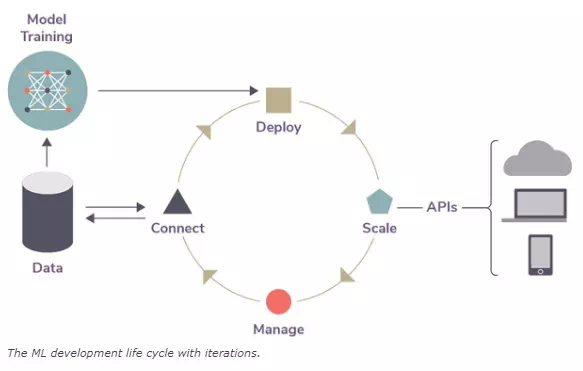
Machine learning is fundamentally different from traditional software development applications and requires its own, unique process: the ML development life cycle.
More and more companies are deciding to build their own, internal ML platforms and are starting down the road of the ML development life cycle. Doing so, however, is difficult and requires much coordination and careful planning. In the end, though, companies are able to control their own ML futures and keep their data secure.
After years of helping companies achieve this goal, we have identified five challenges every organization should keep in mind when they build infrastructure to support ML development.
Heterogeneity
Depending on the ML use case, a data scientist might choose to build a model in Python, R, or Scala and use an entirely different language for a second model. What’s more, within a given language, there are numerous frameworks and toolkits available. TensorFlow, PyTorch, and Scikit-learn all work with Python, but each is tuned for specific types of operations, and each outputs a slightly different type of model.
ML–enabled applications typically call on a pipeline of interconnected models, often written by different teams using different languages and frameworks.
Iteration
In machine learning, your code is only part of a larger ecosystem—the interaction of models with live, often unpredictable data. But interactions with new data can introduce model drift and affect accuracy, requiring constant model tuning and retraining.
As such, ML iterations are typically more frequent than traditional app development workflows, requiring a greater degree of agility from DevOps tools and staff for versioning and other operational processes. This can drastically increase work time needed to complete tasks.
Infrastructure
Machine learning is all about selecting the right tool for a given job. But selecting infrastructure for ML is a complicated endeavor, made so by a rapidly evolving stack of data science tools, a variety of processors available for ML workloads, and the number of advances in cloud-specific scaling and management.
To make an informed choice, you should first identify project scope and parameters. The model-training process, for example, typically involves multiple iterations of the following:
· an intensive compute cycle
· a fixed, inelastic load
· a single user
· concurrent experiments on a single model
After deployment and scale, ML models from several teams enter a shared production environment characterized by:
· short, unpredictable compute bursts
· elastic scaling
· many users calling many models simultaneously
Operations teams must be able to support both of these very different environments on an ongoing basis. Selecting an infrastructure that can handle both workloads would be a wise choice.