Knowledge Organization and Management
The advantage of using structured knowledge representation schemes (frames, associative networks, or object-oriented structures) over unstructured ones (rules or FOPL clauses) should be understood and appreciated at this point. Structured schemes group or link small related chunks of knowledge together as a unit. This simplifies the processing operations, since knowledge required for a given task is usually contained within a limited semantic region, which can be accessed as a unit or traced through a few linkages. But, as suggested earlier, representation is not the only factor, which affects efficient manipulation. A program must first locate and retrieve the appropriate knowledge in an efficient manner whenever it is needed. One of the most direct methods for finding the appropriate knowledge is exhaustive search or the enumerations of all items in memory. This is also one of the least efficient access methods. More efficient retrieval is accomplished through some form of indexing or grouping. We consider some of these processes in the next section where we review traditional access and retrieval methods used in memory organizations. This is followed by a description of less commonly used forms of indexing.
A “smart” expert system can be expected to have thousands or even tens of thousands of rules (or their equivalent) in its KB. A good example is XCON (or RI), an expert system which was developed for the Digital Equipment Corporation to configure their customer’s computer systems. XCON has a rapidly growing KB, which, at the present time, consists of more than 12,000 production rules. Large numbers of rules are needed in systems like this, which deal with complex reasoning tasks. System configuration becomes very complex when the number of components and corresponding parameters is large (several hundred). If each rule contained above four or five conditions in its antecedent or If part and an exhaustive search was used, as many as 40,000-50,000 tests could be required on each recognition cycle. Clearly, the time required to perform this number of tests is intolerable. Instead, some form of memory management is needed. We saw one way this problem was solved using a form of indexing with the RETE algorithm described in the preceding chapter, More direct memory organization approaches to this problem are considered in this chapter.
We humans live in a dynamic, continually changing environment. To cope with this change, our memories exhibit some rather remarkable properties. We are able to adapt to varied changes in the environment and still improve our performance. This is because our memory system is continuously adapting through a reorganization process. New knowledge is continually being added to our memories, existing knowledge is continually being revised, and less important knowledge is gradually being forgotten. Our memories are continually being reorganized to expand our recall and reasoning abilities. This process leads to improved memory performance throughout most of our lives.
When developing computer memories for intelligent systems, we may gain some useful insight by learning what we can from human memory systems. We would expect
computer memory systems to possess some of the same features. For example, human memories tend to be limitless in capacity, and they provide a uniform grade of recall service, independent of the amount of information store. For later use, we have summarized these and other desirable characteristics that we feel an effective computer memory organization system should possess.
1. It should be possible to add and integrate new knowledge in memory as needed without concern for limitations in size.
2. Any organizational scheme chosen should facilitate the remembering process. Thus, it should be possible to locate any stored item of knowledge efficiently from its content alone.
3. The addition of more knowledge to memory should have no adverse effects on the accessibility of items already stored there. Thus, the search time should not increase appreciably with the amount of information stored.
4. The organization scheme should facilitate the recognition of similar items of knowledge. This is essential for reasoning and learning functions. It suggests that
existing knowledge be used to determine the location and manner in which new knowledge is integrated into memory.
5. The organization should facilitate the process of consolidating recurrent incidents or episodes and “forgetting” knowledge when it is no longer valid or no longer needed.
These characteristics suggest that memory be organized around conceptual clusters of knowledge. Related clusters should be grouped and stored in close proximity to each
other and be linked to similar concepts through associative relations. Access to any given cluster should be possible through either direct or indirect links such as concept pointers indexed by meaning. Index keys with synonomous meanings should provide links to the same knowledge clusters. These notions are illustrated graphically in Fig 9.1 where the clusters represent arbitrary groups closely related knowledge such as objects and their properties or basic conceptual categories. The links connecting the clusters are two-way pointers which provide relational associations between the clusters they connect.
Indexing and retrieval techniques
The Frame Problem
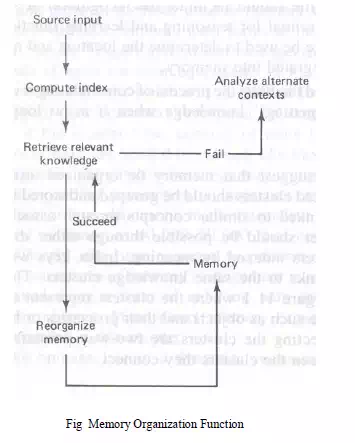
One tricky aspect of systems that must function in dynamic environments is due to the so called frame problem. This is the problem of knowing what changes have and have not taken place following some action. Some changes will be the direct result of the action. Other changes will be the result of secondary or side effects rather than the result of the action. Foe example, if a robot is cleaning the floors in a house, the location of the floor sweeper changes with the robot even though this is not explicitly stated. Other objects not attached to the robot remain in their original places. The actual changes must somehow be reflected in memory, a fear that requires some ability to infer. Effective memory organization and management methods must take into account effects caused by the frame problem The three basic problems related to knowledge organization:
1. classifying and computing indices for input information presented to system
2. access and retrieval of knowledge from mrmory through the use of the computed indices
3. the reorganization of memory structures when necessary to accommodate additions, revisions and forgetting.
These functions are depicted in Fig 9.1
· When a knowledge base is too large to be held in main memory, it must be stored as a file in secondary storage (disk, drum or tape).
· Storage and retrieval of information in secondary memory is then performed through the transfer of equal-size physical blocks consisting of between 256 and 4096 bytes.
· When an item of information is retrieved or stored, at least one complete block must be transferred between main and secondary memory.
· The time required to transfer a block typically ranges between 10ms and 100ms, about the same amount of time required to sequentially searching the whole block for an item.
· Grouping related knowledge together as a unit can help to reduce the number of block transfers, hence the total access time
· An example of effective grouping can be found in some expert system KB organizations
· Grouping together rules which share some of the same conditions and conclusions can reduce block transfer times since such rules are likely to be needed during the same problem solving session
· Collecting rules together by similar conditions or content can help to reduce the number of block transfers required
Indexed Organization
· While organization by content can help to reduce block transfers, an indexed organization scheme can greatly reduce the time to determine the storage location of an item
· Indexing is accomplished by organizing the information in some way for easy access
· One way to index is by segregating knowledge into two or more groups and storing the locations of the knowledge for each group in a smaller index file
· To build an indexed file, knowledge stored as units is first arranged sequentially by some key value
· The key can be any chosen fields that uniquely identify the record
· A second file containing indices for the record locations is created while the sequential knowledge file is being loaded
· Each physical block in this main file results in one entry in the index file
· The index file entries are pairs of record key values and block addresses
· The key value is the key of the first record stored in the corresponding block
· To retrieve an item of knowledge from the main file, the index file is searched to find the desired record key and obtain the corresponding block address
· The block is then accessed using this address. Items within the block are then searched sequentially for the desired record
· An indexed file contains a list of the entry pairs (k,b) where the values k are the keys of the first record in each block whose starting address is b
· Fig 9.2 illustrates the process used to locate a record using the key value of 378

· The largest key value less than 378 (375) gives the block address (800) where the item will be found
· Once the 800 block has been retrieved, it can be searched linearly to locate the record with key value 378. this key could be any alphanumeric string that uniquely identifies a block, since such strings usually have a collation order defined by their code set
· If the index file is large, a binary search can be used to speed up the index file search
· A binary search will significantly reduce the search time over linear search when the number of items is not too small
· When a file contains n records, the average time for a linear search is proportional to n/2 compared to a binary search time on the order of ln2(n)
· Further reductions in search time can be realized using secondary or higher order arranged index files
· In this case the secondary index file would contain key and block address pairs for the primary index file
· Similar indexing would apply for higher order hierarchies where a separate file is used for each level
· Both binary search and hierarchical index file organization may be needed when the KB is a very large file
· Indexing in LISP can be implemented with property lists, A-lists, and/or hash tables. For example, a KB can be partitioned into segments by storing each segment as a list under the property value for that segment
· Each list indexed in this way can be found with the get property function and then searched sequentially or sorted and searched with binary search methods
· A hash-table is a special data structure in LISP which provides a means of rapid access through key hashing
Hashed Files
· Indexed organizations that permit efficient access are based on the use of a hash function
· A hash function, h, transforms key values k into integer storage location indices through a simple computation
· When a maximum number of items C are to stored, the hashed values h(k) will range from 0 to C – 1. Therefore, given any key value k, h(k) should map into
one of 0…C – 1
· An effective hash function can be computed by choosing the largest prime number p less than or equal to C, converting the key value k into an integer k’
if necessary, and then using the value k’ mod p as the index value h
· For example, if C is 1000, the largest prime less than C is p = 997. thus, if the record key value is 123456789, the hashed value is h = (k mod 997) = 273
· When using hashed access, the value of C should be chosen large enough to accommodate the maximum number of categories needed
· The use of the prime number p in the algorithm helps to insure that the resultant indices are somewhat uniformly distributed or hashed throughout the
range 0 . . . C – 1
· This type of organization is well suited for groups of items corresponding to Cdifferent categories
· When two or more items belong to the same category, they will have the samehashed values. These values are called synonyms
· One way to accommodate collisions is with data structures known as buckets
· A bucket is a linked list of one or more items, where each item is record, block, list or other data strucyure
· The first item in each bucket has an address corresponding to the hashed address
· Fig 9.3 illustrates a form of hashed memory organization which uses buckets to hold all items with the same hashed key value
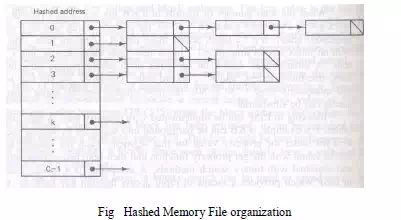
· The address of each bucket in this case is the indexed location in an array
Conceptual Indexing
· A better approach to indexed retrieval is one which makes use of the content or meaning associated with the stored entities rather than some nonmeaningful
key value
· This suggests the use of indices which name and define the entity being retrieved. Thus, if the entity is an object, its name and characteristic attributes would make meaningful indices
· If the entity is an abstract object such as a concept, the name and other defining traits would ne meaningful as indices
· Nodes within the network correspond to different knowledge entities, whereas the links are indices or pointers to the entities
· Links connecting two entities name the association or relationship between them
· The relationship between entities may be defined as a hierarchical one or just through associative links
· As an example of an indexed network, the concept of computer science CS should be accessible directly through the CS name or indirectly through associative links like a university major, a career field, or a type of classroom course
· These notions are illustrated in Fig 9.4

· Object attributes can also serve as indices to locate items based on the attribute values
· In this case, the best attribute keys are those which provide the greatest discrimination among objects within the same category
· For example, suppose we wish to organize knowledge by object types. In this case, the choice of attributes should depend on the use intended for the knowledge. Since objects may be classified with an unlimited number of attributes , those attributes which are most discriminable with respect to the concept meaning should be chosen
Integrating knowledge and memory
· Integrating new knowledge in traditional data bases is accomplished by simply adding an item to its key location, deleting an item from a key directed location, or modifying fields of an existing item with specific input information.
· When an item in inventory is replaced with a new one, its description is changed accordingly. When an item is added to memory, its index is computed and it is stored at the corresponding address
· More sophisticated memory systems will continuously monitor a knowledge base and make inferred changes as appropriate
· A more comprehensive management system will perform other functions as well, including the formation of new conceptual structures, the computation and association of casual linkages between related concepts, generalization of items having common features and the formation of specialized conceptual categories and specialization of concepts that have been over generalized
Hypertext
· Hypertext systems are examples of information organized through associative links, like associative networks
· These systems are interactive window systems connected to a database through associative links
· Unlike normal text which is read in linear fashion, hypertext can be browsed in a nonlinear way by moving through a network of information nodes which are linked bidirectionally through associative
· Users of hypertext systems can wander through the database scanning text and graphics, creating new information nodes and linkages or modify existing ones
· This approach to documentation use is said to more closely match the cognitive process
· It provides a new approach to information access and organization for authors,researchers and other users of large bodies of information
Memory organization system
· HAM, a model of memory
· One of the earliest computer models of memory was the Human Associative memory (HAM) system developed by John Anderson and Gordon Bower
· This memory is organized as a network of prepositional binary trees
· An example of a simple tree which represents the statement “In a park s hippie touched a debutante” is illustrated in Fig 9.5
· When an informant asserts this statement to HAM, the system parses the sentence and builds a binary tree representation
· Node in the tree are assigned unique numbers, while links are labeled with the following functions:
C: context for tree fact P: predicate
e: set membership R: relation
F: a fact S: subject
L: a location T: time
O: object
· As HAM is informed of new sentences, they are parsed and formed into new tree-like memory structures or integrated with existing ones
· For example, to add the fact that the hippie was tall, the following subtree is attached to the tree structure of Fig below by merging the common node hippie (node 3) into a single node

· When HAM is posed with a query, it is formed into a tree structure called a probe. This structure is then matched against existing memory structures for the best match
· The structure with the closest match is used to formulate an answer to the query
· Matching is accomplished by first locating the leaf nodes in memory that match leaf nodes in the probe
· The corresponding links are then checked to see if they have the same labels and in the same order
· The search process is constrained by searching only node groups that have the same relation links, based on recency of usage
· The search is not exhaustive and nodes accessed infrequently may be forgotten
· Access to nodes in HAM is accomplished through word indexing in LISP
Memory Organization with E-MOPs
· One system was developed by Janet Kolodner to study problems associated with the retrieval and organization of reconstructive memory, called CYRUS
(Computerized Yale Retrieval and Updating System) stores episodes from the lives of former secretaries of state Cyrus Vance and Edmund Muskie
· The episodes are indexed and stored in long term memory for subsequent use in answering queries posed in English
· The basic memory model in CYRUS is a network consisting of Episodic Memory Organization Packets (E-MOPs)
· Each such E-MOP is a frame-like node structure which contains conceptual information related to different categories of episodic events
· E-MOP are indexed in memory by one or more distinguishing features. For example, there are basic E-MOPs for diplomatic meetings with foreign dignitaries, specialized political conferences, traveling, state dinners as well as other basic events related to diplomatic state functions
· This diplomatic meeting E-MOP called $MEET, contains information which is common to all diplomatic meeting events
· The common information which characterizes such as E-MOP is called its content
· For example, $MEET might contain the following information:
· A second type of information contained in E-MOPs are the indices which index either individual episodes or other E-MOPs which have become specializations of their parent E-MOPs
· A typical $MEET E-MOP which has indices to two particular event meetings EV1 and EV2, is illustrated in Fig 9.6
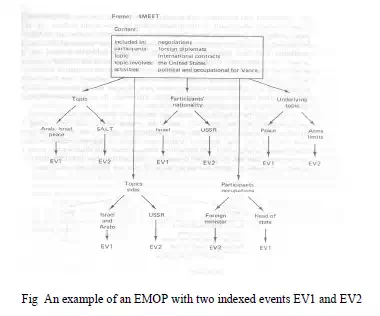
· For example, one of the meetings indexed was between Vance and Gromyko of the USSR in which they discussed SALT. This is labeled as event EV1 in the figure. The second meeting was between Vance and Begin of Israel in which they discussed Arab-Israeli peace. This is labeled as event EV2
· Note that each of these events can be accessed through more than one feature (index). For example, EV1 can be located from the $MEET event through a topic value of “Arab-Israel peace,” through a participants’ nationality value of “Israel,” through a participants’ occupation value of “head of state,” and so on
· As new diplomatic meetings are entered into the system, they are either integrated with the $MEET E-MOP as a separately indexed event or merged with another event to form a new specialized meeting E-MOP.
· When several events belonging to the same MOP category are entered, common event features are used to generalize the E-MOP. This information is collected in the frame contents. Specialization may also be required when over-generalization has occurred. Thus, memory is continually being reorganized as new facts are entered.
· This process prevents the addition of excessive memory entries and much redundancy which would result if every event entered resulted in the addition of a separate event
· Reorganization can also cause forgetting, since originally assigned indices may be changed when new structures are formed
· When this occurs, an item cannot be located, so the system attempts to derive new indices from the context and through other indices by reconstructing related events
· The key issues in this type of the organizations are:
· The selection and computation of good indices for new events so that similar events can be located in memory for new event integration
· Monitoring and reorganization of memory to accommodate new events as they occur
· Access of the correct event information when provided clues for retrieval