Brute-Force Search Strategies
They are most simple, as they do not need any domain-specific knowledge. They work fine with small number of possible states.
Requirements −
● State description
● A set of valid operators
● Initial state
● Goal state description
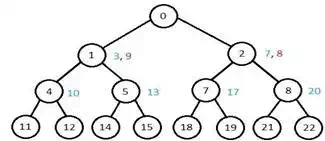
Breadth-First Search
It starts from the root node, explores the neighboring nodes first and moves towards the next level neighbors. It generates one tree at a time until the solution is found. It can be implemented using FIFO queue data structure. This method provides shortest path to the solution.
If branching factor (average number of child nodes for a given node) = b and depth = d, then number of nodes at level d = bd.
The total no of nodes created in worst case is b + b2 + b3 + … + bd.
Disadvantage − Since each level of nodes is saved for creating next one, it consumes a lot of memory space. Space requirement to store nodes is exponential.
Its complexity depends on the number of nodes. It can check duplicate nodes.
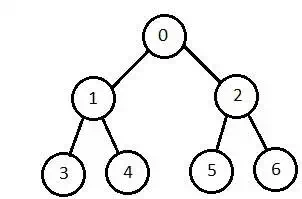
Depth-First Search
It is implemented in recursion with LIFO stack data structure. It creates the same set of nodes as Breadth-First method, only in the different order.
As the nodes on the single path are stored in each iteration from root to leaf node, the space requirement to store nodes is linear. With branching factor b and depth as m, the storage space is bm.
Disadvantage − This algorithm may not terminate and go on infinitely on one path. The solution to this issue is to choose a cut-off depth. If the ideal cut-off is d, and if chosen cut-off is lesser than d, then this algorithm may fail. If chosen cut-off is more than d, then execution time increases.
Its complexity depends on the number of paths. It cannot check duplicate nodes.
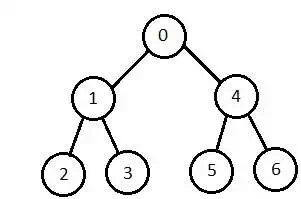
Bidirectional Search
It searches forward from initial state and backward from goal state till both meet to identify a common state.
The path from initial state is concatenated with the inverse path from the goal state. Each search is done only up to half of the total path.
Uniform Cost Search
Sorting is done in increasing cost of the path to a node. It always expands the least cost node. It is identical to Breadth First search if each transition has the same cost.
It explores paths in the increasing order of cost.
Disadvantage − There can be multiple long paths with the cost ≤ C*. Uniform Cost search must explore them all.
Iterative Deepening Depth-First Search
It performs depth-first search to level 1, starts over, executes a complete depth-first search to level 2, and continues in such way till the solution is found.
It never creates a node until all lower nodes are generated. It only saves a stack of nodes. The algorithm ends when it finds a solution at depth d. The number of nodes created at depth d is bd and at depth d-1 is bd-1.