Developing a Bioinformatics Database for Disulfide Bonds Research
The Protein Data Bank (PDB) bioinformatics database is the world’s largest repository of experimentally-determined structures of proteins, nucleic acids, and complex assemblies. All data is gathered using experimental methods such as X-ray, spectroscopy, crystallography, NMR, etc.
The PDB has a lot of repeating structures with different resolutions, methods, mutations, etc. Doing an experiment with the same or similar proteins can produce bias in any group analysis, so we will need to choose the correct structure from among any set of duplicates. For that purpose, we need to use a non-redundant (NR) set of proteins.
For the purpose of normalization, I recommend downloading the chemical compound dictionary for importing atom names into a database that uses 3NF or uses a star schema and dimensional modeling. (I’ve also used DSSP to help eliminate problematic structures. I won’t cover that in this article, but note that I didn’t use any other DSSP features.)
Data used in this research contains single-unit proteins who contain at least one disulfide bond taken from different species. To perform an analysis, all disulfide bonds are first classified as consecutive or nonconsecutive, by domain (archaea, prokaryote, viral, eukaryote, or other), and also by length.
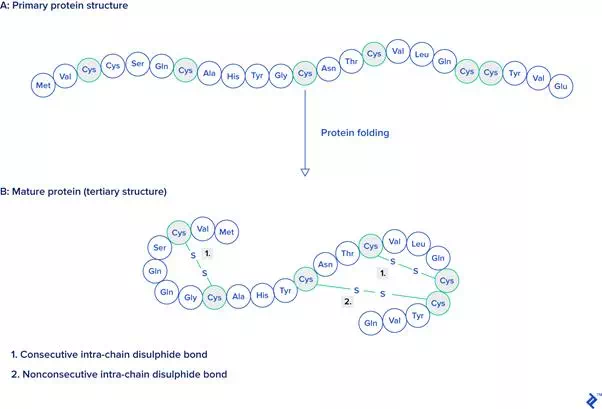
Primary and tertiary protein structures, before and after protein folding.
Output
To be ready for input into R, SPSS, or some other tool, an analyst will need the data to be in a database table with this structure:
|
Column |
Type |
Description |
|
|
|
Experiment ID (alphanumeric, case-insensitive, and cannot start with a zero) |
|
|
|
Title of the experiment, for reference (field can be also text format) |
|
|
|
Number of disulfide bonds in the chosen chain |
|
|
|
Number of overlapping disulfide bonds |
|
|
|
Number of bonds made within the same chain |
|
|
|
Scientific name of organism from which the sequence is taken |
|
|
|
Path in Linnaean classification tree |
|
|
|
Top-level class of organism (eukaryote, prokaryote, virus, archaea, other) |
|
|
|
True if and only if the sequence contains reactive centers |
|
|
|
Length of sequence in set 7 (set with p-value 10e-7 calculated by blast) |