Timing Analysis
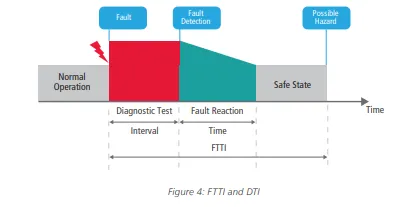
Though the hardware architectural metrics described so far do not include timing constraints, it is easy to understand that the complete evaluation of the safety mechanisms shall involve timing performance. In fact, the system must be able to detect faults and transition to a safe state within a specific time, or fault tolerant time interval (FTTI); otherwise, the fault can become a system-level hazard. This is captured in Figure 4, which also illustrates the diagnostic test interval (DTI), the part of FTTI allotted to detect the fault (ISO 26262: Road vehicles — Functional safety). Just as a reference example, the DTI for fault detection in a CPU can be around 10ms, while around 100ms would be allocated for FTTI of the whole system.
DFA
Together with the analysis of hardware random failures, another aspect to evaluate, especially when the system has shared resources, is the dependent failure analysis (DFA).
The analysis of dependent failures—also known as analysis of possible common cause and cascading failures between given elements—aims to identify the single causes that could bypass a required independence or freedom from interference between given elements and violate a safety requirement or a safety goal (ISO 26262: Road vehicles — Functional safety).
Two most intuitive scenarios associated with architectural features are:
– Similar and dissimilar redundant elements
– Different functions implemented with identical software or hardware elements
ISO 26262 provides a list of dependent failure initiators to evaluate and guidelines on safety measures to control or mitigate this kind of faults.
Examples of dependent failure initiators due to random hardware faults of shared resources are failures in clock elements, power supply elements or common reset logic. Dependent failure initiators associated with random physical root causes include, for example, short circuits, latch up and crosstalk.
Per ISO 26262, typical countermeasures for random physical root causes include:
– Dedicated independent monitoring of shared resources (e.g., clock monitoring)
– Self-tests at start-up (e.g,. safety mechanism enabling check)
– Diversification of impact (e.g., clock delay between master and checker core)
– Indirect monitoring using special sensors (e.g,. delay lines used as common-cause failure sensors)
– Fault avoidance measures (e.g., physical separation/isolation)