Human Action Recognition with RGB-D Sensors
The topic known as human action recognition (HAR) has become of interest in the last years mainly because different applications can be developed from the understanding of human behaviors. The technologies used to recognize activities can be varied and based on different approaches. The use of environmental and acoustic sensors allows to infer the activity from the interaction of the user with the environment and the objects located in it, but vision-based solutions and wearable devices are usually the most used technologies to detect human body movements. RGB-D sensors, i.e., Red-Green-Blue and depth sensors, can be considered as enhanced vision-based devices since they can additionally provide depth data that can facilitate the detection of human movements. In fact, depth information may help to improve the performance of HAR algorithms because it is easier to implement a crucial process such as the extraction of human silhouette, reducing its dependence from shadows, light reflections, and color similarity. Skeleton joints, which can be even exploited to calculate features for action recognition, are extracted from depth data.
The aim of this chapter is to discuss HAR algorithms exploiting RGB-D sensors, providing a review of the most salient methods proposed in literature and an overview of nonvision-based devices. A method for HAR exploiting skeleton joints and known as temporal pyramid of key poses is described and experimental results on a well-known RGB-D dataset are provided.
Section 2 of this chapter aims to review methods for human action recognition based on different technologies, with a particular focus on RGB-D data. An algorithm based on histograms of key poses exploiting skeleton joints extracted by Kinect is presented in Section 3. Finally, the last section of the chapter highlights the main conclusion on the proposed topic.
Methods and technologies for HAR
HAR methods can be implemented on data gathered from different technologies, which can infer the action from the movements made by the person, or from the interaction with objects or the environment. A review of sensors and technologies for detection of different human activities in smart homes can be found in Ref., where the aim is to face the phenomenon of aging population. Following the same unobtrusive approach, researchers are working also on radio-based techniques, where they take advantage of signal attenuation due to the body, and channel fading of wireless radio. Other works have been also published considering wearable devices, such as smartphones, that can be used to collect data and to classify actions. A more general architecture implemented with wearable devices requires the usage of small sensors with sensing and communication capabilities that can acquire data (usually related to acceleration) and send them to a central unit.
RELATED WORKS ON NOT VISION-BASED DEVICES
HAR based on data generated by environmental devices in home environment may exploit unobtrusive sensors equipping objects with which people usually interact, or other sensors that are installed in the rooms. State-changes sensors, which activate and deactivate if they detect a change, can provide powerful clues about movements in the apartment if placed on windows or doors. If attached to ovens and fridges, or toilet and washing machines, they can reveal kitchen-related activities or activities associated to toileting and doing laundry. Passive infrared sensors (PIRs) detect the presence of a person in a room and a set of activities can be inferred if they are jointly used with other sensors, such as state-changes sensors and flush sensors, to detect the use of the toilet. Multiple binary sensors such as motion detectors, contact switches, break-beam sensors, and pressure mats have been used in Ref. Using an approach based on particle filter and an ID sensor (RFID) to detect people’s identity, the system can reveal information about the occupied rooms and the number of occupants, and recognize if they are moving or not and track their movement. An integrated platform including PIRs, magnetic sensors, force sensors, gas and smoke detection sensors, water and gas flux meters, power meters connected to some objects has been implemented in a laboratory environment. Some simple activities, such as cooking, sitting, watching TV, can be easily inferred by processing the output data of sensors. Environmental sensors can be installed also in nursing homes, to support and help assistance of Alzheimer’s disease patients. In this scenario, even the detection of simple events such as “presence in bed” or “door opening” may be relevant to ensure comfort and safety of patients. Environmental sensors are completely unobtrusive and privacy preserving but they usually require some time for the installation. Furthermore, the amount of information that can be obtained from the sensors is limited, and does not include the extraction of human movements.
Other unobtrusive sensors revealing the interaction with the environment can be audio sensors. In fact, some activities generate sounds that can be captured using one or multiple microphones. Characteristic sounds are generated for example by chatting or reading newspapers activities, as well as drink and food intake events, that can be classified considering their features. Tremblay et al. proposed an algorithm to recognize a limited set of activities from six microphones installed at different positions in a test apartment. Two activities of daily living (ADLs), i.e., breakfast and household, constituted by multiple steps have been recognized with a promising accuracy. Multiple audio sensors in the same apartment could constitute a wireless sensor network (WSN), addressing the challenges of limited amount of memory and processing power of the nodes. However, it has been proven that low complexity features extraction algorithms can be adopted with good performance considering the indoor scenario. Vuegen et al. ] proposed a WSN constituted by seven nodes placed in different rooms: living room/kitchen, bedroom, bathroom and toilet, covering the entire apartment. A set of 10 ADLs has been recorded considering two test users and an artificial dataset to examine the influence of background noise. Acoustic sensors can be adopted in assistive environments to detect dangerous events such as falls.
Radio-based techniques do not require any physical sensing module and they may work without the need of wearing any device, but only exploiting the existing WiFi links between the access point and connected devices. With one access point and three devices, a set of nine in-place activities (such as cooking, eating, washing dishes, etc.) and eight walking activities (distinguishing the direction of movement within the apartment) can be recognized. Another radio-based technique is represented by micro-Doppler signatures (MDS). Commercial radar motes can be used to discern among a small set of activities, such as walking, running, and crawling, with high accuracy values. A larger set of MDS captured from humans performing 18 movements has been collected and presented in Ref. Activities have been grouped in three categories: stationary, forward-moving and multitarget, and characterized both in free-space and through-wall environments, associating the general properties of the signatures to their phenomenological characteristics. Björklund et al. included a set of five activities (crawling, creeping on their hands and knees, walking, jogging, and running) in their study. They evaluated the performance of an activity recognition algorithm based on a support vector machine (SVM) with features in the time-velocity domain and in the cadence-velocity domain, obtaining comparable results of about 90% of accuracy.
Wearable sensors can be used to extract the human movements since they usually provide acceleration data. Considering inertial data, many different features for human action recognition have been proposed, with the aim to reduce the complexity of the features extraction process and to enhance the separation among the classes. Wearable inertial sensors are quite cheap and generate a limited amount of data that can be processed easily with respect to video data, even if they do not provide information about the context. The placement of wearable sensors can be an issue and this step has to be carefully addressed. This choice mainly depends on the movements constituting the set of activities that have to be recognized. The placement on the waist of the subject is close to the center of mass, and can be used to represent activities involving the whole body. With this configuration, sitting, standing, and lying postures can be detected with a high degree of accuracy considering a dataset acquired in a laboratory environment. The placement on the subject’s waist, as well as the one on the subject’s chest or knee, gives good results with transitional activities also in Ref. On the other hand, high level activities such as running (in a corridor or on a treadmill) and cycling are revealed mostly by an ear worn sensor, since it measures the change in body posture. The placement of wearable unit on the dominant wrist may help the discrimination of upper body movements constituting for example the activities of brushing teeth, vacuuming, and working at computer. On the other hand, the recognition of gait-related activities, such as normal walking, stair descending, stair ascending, and so on, requires the positioning of the devices on the lower limbs. In particular, even if the shank’s sensor could be enough to predict the activities, the usage of other IMUs, placed on tight, foot and waist, can enhance the final accuracy. A multisensor system for activity recognition usually allows to increase the accuracy with respect to a single-sensor system, even if the latter employs a higher sampling rate, more complex features and a more sophisticated classifier. The main drawback is the increasing level of obtrusiveness for the subject being monitored. Furthermore, if it may be acceptable to ask people to wear a device for a limited amount of time, for example to extract some parameters during movement assessment test, it may be unacceptable to request wearing several IMUs to continuously track ADLs.
RELATED WORKS ON RGB-D SENSORS
Video-based devices (and especially RGB-D sensors) allow to extract activities from body movements but they are not obtrusive and they do not pose many issues about installation as environmental sensors do. Furthermore, RGB-D sensors do not raise problems related to radiation impact, differently from radar-based techniques, which can limit their acceptability. On the other hand, video-based sensors may be deemed not acceptable for privacy concerns but RGB-D sensors provide not negligible advantages from this point of view. In fact, when the data processing algorithms exploit only depth information, the privacy of the subject is preserved because no plain images are collected, and many details cannot be extracted from depth signal only. Different levels of privacy can be considered according to the user’s preferences, thanks to the possibility to extract the human silhouette, or even to represent the human subject only by means of the skeleton.
Many different reviews on HAR based on vision sensors have been published in the past, each of which proposing its own taxonomy to classify different approaches. Aggarwal and Xia, in their review, considered only methods based on 3D data that can be obtained from three different technologies: marker-based systems, stereo images or range sensors, and organizing the papers in five categories based on the features considered.
The review of action recognition algorithms based on RGB-D sensors is organized considering the data processed by the algorithms, separating methods based on depth data from others exploiting skeleton information. Due to the simple extraction process of the silhouette from depth data, approaches based on this information may exploit features extracted from silhouettes. Li et al. calculate a bag of 3D points from human silhouette, sampling the points on the contours of the planar projections of the 3D depth map. An action graph, where each node is associated to a salient posture, is adopted to explicitly model the dynamics of the actions. Features from 2D silhouettes have been considered in Ref., where an action is modeled as a sequence of key poses, extracted by means of a clustering algorithm, from a training dataset. Dynamic time warping (DTW) is suitable in this case because sequences can be inconsistent in terms of time scale, but they preserve the time order, and DTW can associate an unknown sequence of key poses to the closest sequence in the training set, thus performing the recognition process. Other approaches exploiting depth data considered the extraction of local or holistic descriptors. Local spatio-temporal interest points (STIPs), which have been used with RGB data, can be adapted to depth including additional strategies to reduce the noise typical of depth data, such as the inaccurate identification of objects’ borders, or the presence of holes in the frame. A spatio-temporal subdivision of the space in multiple segments has been proposed in Ref., where the occupancy patterns are extracted from a 4D grid. Holistic descriptors, namely histogram of oriented 4D normals (HON4D) and histogram of oriented principal components (HOPC) have been exploited respectively in Refs.. HON4D is based on the orientation of normal surfaces in 4D while HOPC can represent the geometric characteristics of a sequence of 3D points.
Skeleton joints represent a compact and effective description of the human body, for this reason they are assumed and exploited as input data by many action recognition algorithms. Kinect sensor provides 3D coordinates of 20 skeleton joints, thus motion trajectories in a 60-dimensional space can be associated to human motion. A trajectory is the evolution of the positions of joint coordinates along a sequence of frames related to an action. A kNN classifier learns the trajectories of different actions and performs classification. Gaglio et al. proposed an algorithm constituted by three steps: features detection, where the skeleton coordinates are elaborated to extract features; posture analysis, that consists in the detection of salient postures through a clustering algorithm and their classification with a support vector machine (SVM); and activity recognition, where a sequence of postures is modeled by an hidden Markov model (HMM). In Ref., the coordinates of human skeleton models generate body poses and an action can be seen as a sequence of body poses over time. According to this approach, a feature vector is obtained representing each pose in a multidimensional feature space. A movement can be now represented as a trajectory in the feature space, which may constitute a signature of the associated action, if the transformation and features are carefully chosen. An effective representation based on skeleton joints is called APJ3D, which is built from 3D joint locations and angles. The key postures are extracted by a k-means clustering algorithm and, following a representation through an improved Fourier temporal pyramid, the recognition task is carried out with random forests. Xia et al. proposed a method to compactly represent human postures with histograms of 3D joints (HOJ3D). The positions of the joints are translated into a spherical coordinate system and, after a reprojection of the HOJ3D vectors using linear discriminant analysis (LDA), a number of key postures are extracted from training sequences. The temporal evolution of postures is modeled through HMM.
Research on HAR using RGB-D sensors has been fostered by the release of many datasets. An extensive review of the datasets collected for different purposes, going for example from camera tracking and scene reconstruction to pose estimation or semantic reasoning, can be found in Ref. [49]. Another review, which is focused on RGB-D datasets for HAR, has been published in Ref. In the latter work, the datasets have been organized considering the methods applied for data collection, which can include a single view setup, with one capturing device, a multiview setup with more devices, or a multiperson setup where some interactions among different people are included in the set of classes.
A list of the most used datasets for HAR is provided in Table 1, where different features of each dataset are highlighted. Many datasets provide the most important data streams available with a RGB-D device, i.e., the color and depth frames along with skeleton coordinates. They are usually featured by a number of actions between 10 and 20, performed by different subjects (around 10), and repeated 2 or 3 times. Considering the set of actions included in the datasets, they can be used for two main applications that are the detection of daily activities (DA) and the human computer interaction (HCI). Datasets belonging to the first group usually include actions like walking, eating, drinking, and sometimes they are recorded in a real scenario, which introduces partial occlusions and a complex background. Datasets focused on HCI applications may contain actions like draw x, draw circle, side kick, and they are usually captured with a simpler background, even if they can be challenging, due to the similarity of many gestures and to the differences in speeds and way to perform the movement, considering different actors.
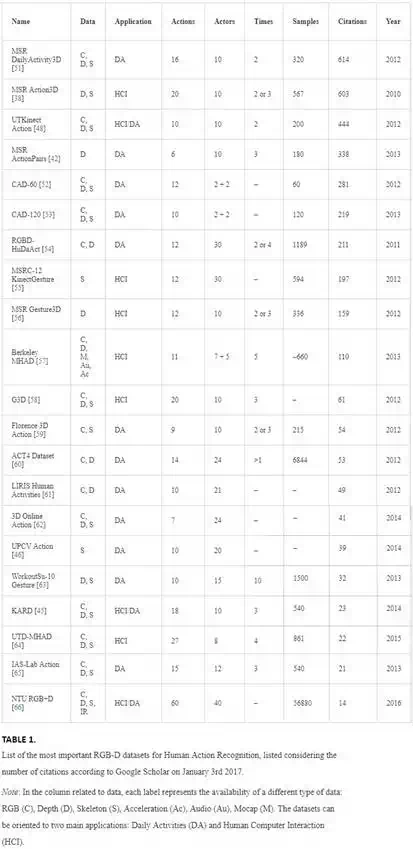
The oldest and the newest datasets included in the list are deeply discussed because of their characteristics. MSR Action3D was the first relevant dataset for HAR, it has been released in 2010 and it includes 20 actions that are suitable for HCI. The following activities are included in the dataset: high arm wave, horizontal arm wave, hammer, hand catch, forward punch, high throw, draw x, draw tick, draw circle, hand clap, two hand wave, side boxing, bend, forward kick, side kick, jogging, tennis swing, tennis serve, golf swing, pick-up, and throw. As described in Ref., the dataset has been often evaluated considering three subsets of 8 actions each, namely AS1, AS2, and AS3. As can be noticed from Table 2, AS1 and AS2 are built by grouping actions with similar movements, and AS3 includes actions that require more complex movements. From Figure 1 it is possible to observe sequences of frames constituting two similar actions in AS1: hammer and forward punch. Sequences of frames from Draw x and Draw tick, two similar actions in AS2, are shown in Figure 2. The dataset has been collected using a structured light depth sensor and the provided data are represented by depth frames, at a resolution of 320 × 240, and skeleton coordinates. The entire dataset includes 567 sequences but, considering that 10 of them are affected by wrong or missing skeletons, only 557 sequences of skeleton joint coordinates are available. The evaluation method usually adopted on this dataset is called cross-subject test and takes into account samples from actors 1-3-5-7-9 for training, and the remaining data for testing. NTU RGB+D is one of the most recent datasets for HAR and, to the authors’ best knowledge, the largest. In fact, it includes 60 different actions that can be grouped in 40 daily actions (reading, writing, wear jacket, take off jacket), 9 health-related actions (falling down, touch head, touch neck), and 11 interactions (walking toward each other, walking apart from each other, handshaking). A number of 40 actors have been recruited to perform the actions multiple times, involving also 17 different setups of the Kinect v2 sensors adopted for data collection. Each action has been captured from three sensors simultaneously, having three different views of the same scene (0°, +45°, −45° directions). All the data provided by Kinect v2 (RGB, depth, infrared frames and skeleton coordinates) are collected and included in the released dataset. Two evaluation methods have been proposed in Ref., aiming to test the goodness of HAR methods with unseen subjects and new views. In the cross-subject test, a specific list of subjects is used for training and the remaining represent the test data, while in the cross-view test the sequences from devices 2 and 3 are used for training and the ones from camera 1 are adopted for testing.
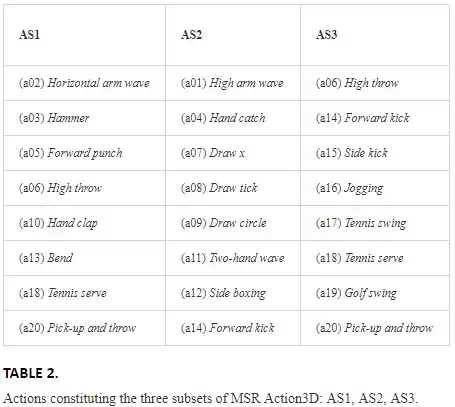
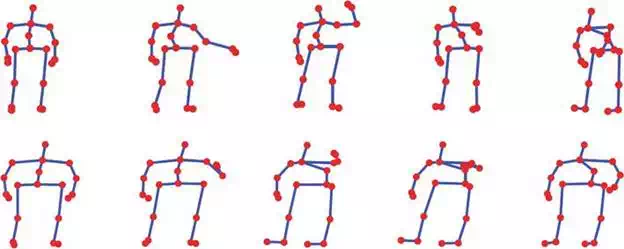
FIGURE 1.
Sequences of frames constituting similar actions in AS1 subset of MSR Action3D: hammer (top) and forward punch (bottom).
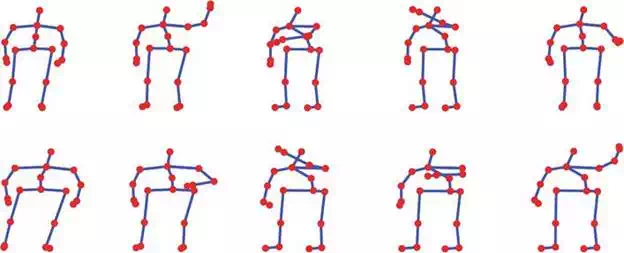
FIGURE 2.
Sequences of frames constituting similar actions in AS2 subset of MSR Action3D: draw x (top) and draw tick (bottom).
Human action recognition based on temporal pyramid of key poses
A HAR method that allows to achieve state-of-the-art results has been proposed in Ref. and can be defined as temporal pyramid of key poses. It exploits the bag of key poses model and it adopts a temporal pyramid to model the temporal structure of the key poses constituting an action sequence.
ALGORITHM OVERVIEW
The algorithm based on temporal pyramid of key poses can be represented by the scheme shown in Figure 3. It performs four main steps that include the extraction of posture features, the adoption of the bag of key poses model, and the representation of the action sequence through a temporal pyramid of key poses; finally, the classification by a multiclass SVM takes place.
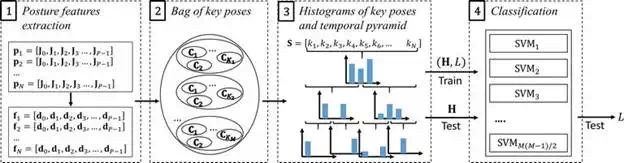
FIGURE 3.
Global scheme of the algorithm based on temporal pyramid of key poses. Step 1 extracts the feature vectors related to posture while step 2 is represented by the bag of key poses model. The third phase exploits the temporal pyramid to model the temporal structure of the sequences and the last step is the classification phase.
The algorithm takes as an input the coordinates of skeleton joints, that can be seen as a 3-dimensional vector Ji for the i-th joint of a body with P joints. The aim of the first step is to obtain view- and position-invariant features from the raw coordinates. The feature computation scheme derives from the one proposed in Ref., but here a virtual joint called center-of-mass is introduced. Considering all the skeleton joints stored in the vector Pn related to the n-th frame of a sequence, the center-of-mass Jcmis calculated by averaging the coordinates of all the P joints. In order to normalize coordinates with respect to the size of the body, the normalization factor s is computed by averaging the L-2 norm between the skeleton joints and Jcm, as follows:
![]()
The normalization with respect to the position of the skeleton is implemented considering the displacement between each joint position and the center-of-mass, normalized by the factor s. Each joint is thus represented by a 3 dimensional vector di:
![]()
Finally, as can be noticed in the first part of Figure 3, each vector pn corresponding to the coordinates of the skeleton in the n-th frame, is translated into a vector fn which includes the features related to that skeleton.
Once the features related to the skeleton have been obtained, the bag of key poses method is adopted to extract the most significant postures and the action is then represented as a sequence of key poses. In more detail, the clustering algorithm k-means is applied considering separately the training sequences of each class, setting a different number of key poses for each action of the dataset, i.e., K1 for class 1, K2for class 2, up to KM if the dataset is constituted by M classes. Following the clustering process performed separately for each class, the key poses, which are the centres of the clusters, have to be merged to obtain a unique codebook. Finally, each posture feature vector is associated to the closest key pose in terms of Euclidean distance, and a sequence of key poses S = [k1, k2, k3, …, kN] represents an action of N frames.
The temporal structure of an action can be represented with the adoption of a temporal pyramid. The idea is to provide different representations of the action: the most general one is provided at the first level of the pyramid, whereas the most detailed one is given at the last level. For each level, the computation of the histograms of key poses is implemented, having at the end of the process a histogram for each segment at each level. Starting from the consideration of the entire sequence at the first level of the pyramid, two segments are considered in the second level and they are split again in two at the third level, giving a number of seven histograms when three levels are considered. These histograms H represent the input data to the final step, which is the classifier.
The classification step aims to associate the data extracted from an unknown data sequence to the correct action label, knowing the training set. In particular, the classifier has to be trained with a set of histograms H for which the action labels L are known. Then, in the testing phase, an unknown H has to be associated to the corresponding L. A multiclass SVM has been chosen for classification purpose. The approach considered for the implementation of the multiclass scheme is defined as “one-versus-one,” where a set of M(M – 1)/2 binary SVMs are required for a dataset of M classes, each of which has to distinguish two classes. The output class is elected with a voting strategy considering the result of each binary SVM.
EXPERIMENTAL RESULTS AND DISCUSSION
This method has been evaluated on one of the most used RGB-D dataset for HAR: MSR Action3D. The test scheme adopted is the cross-subject test, described in the previous section.
The algorithm requires to set different parameters in order to be executed, which are the number of key poses per class (clusters), the set of skeleton joints (features) and the set of training sequences (instances). These parameters can be chosen randomly or using some optimization strategies in order to maximize the performance. In this chapter, results are shown using both the options, adopting the optimization process, based on evolutionary and coevolutionary algorithms. These optimization strategies are applied as wrapper methods, associating the fitness of each individual in the population to the accuracy of the action recognition algorithm.
Since the idea is to optimize three parameters, the structure of each individual is constituted by three parts. The first one is related to features, and it is a binary vector of length P, which is the number of joints in a skeleton. A bin is featured by a 1 value if the associated joint has to be considered by the action recognition algorithm; otherwise it is featured by a 0 value. The same approach is used for the part related to training instances, which is therefore represented by a binary vector of length I. Regarding the optimization of the number of key poses, it is necessary to adopt a vector of integer values with a length of M, where each bin is associated to a class of the dataset, and contains the number of its clusters. Crossover and mutation operators have to be used to evolve the population’s individuals, and a standard 1-point crossover operator is applied for the subindividuals related to instances and clusters. A specific crossover operator which takes into account the structure of the skeleton joints is applied to the features part. Finally, three different mutation probabilities are considered, for the three parts of the individual.
In addition to the evolutionary algorithm, a cooperative coevolutionary optimization method can be also implemented. The main difference between evolutionary and coevolutionary approaches is in the organization of the population of individuals. In particular, in the latter case, each subindividual is part of a different population, thus generating a set of three populations. The selection of one element from each population is necessary to execute the action recognition algorithm and to extract the fitness value, which is associated to each subindividual. Crossover and mutation operators can be applied according to the same considerations made for the evolutionary computation. In order to improve the performance of the optimization process, different priorities are given to the individuals of the populations. In particular, in the populations related to features and instances, the individuals with a lower number of ones are preferred, while in the populations related to clusters, the individuals featuring a lower number of key poses are favored.
The three parameter selection methods can be described as follows:
● Random selection: the number of clusters required by the bag of key poses method is selected randomly within the interval for the subsets AS1 and AS2 and the interval for AS3. All the skeleton joints and training instances are included in the processing.
● Evolutionary optimization: the evolutionary algorithm selects the best combination of skeleton joints and clusters, considering all the training sequences. The same intervals adopted in the random selection are used for the optimization of the number of key poses.
● Coevolutionary optimization: the optimization method selects all the parameters required by the HAR algorithm: features, clusters, and instances. In this case, the intervals for clustersoptimization are for AS1 and AS2, and for AS3.
The results are summarized in Table 3, where it can be noticed that, for all the parameters selection methods, the best results are obtained for AS3, AS1, and finally AS2. In fact, as already stated, subsets AS1 and AS2 group have similar gestures (Figures 1 and 2). More in detail, from Figure 2 it is quite evident that Draw x and Draw tick involve the same poses, and the main cue to differentiate them is their order.
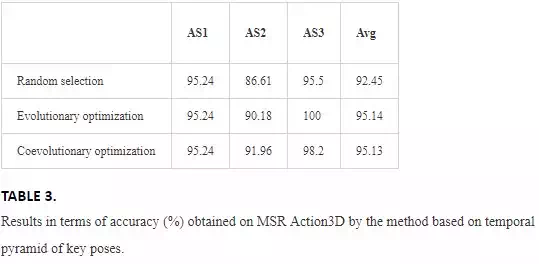
An average accuracy of 92.45% can be achieved considering the random selection of number of key poses. The subset AS2 is the most critical one, with an accuracy of 86.61% due to the aforementioned reasons. Considering evolutionary optimization, where the evaluated parameters are the number of key poses and the set of skeleton joints, there is a noticeable improvement in AS2 and AS3, and the HAR algorithm shows an average accuracy of 95.14%. Similar average results are obtained with the adoption of the coevolutionary optimization method, including also the set of training instances in the optimization process. In particular, there is a further improvement in AS2, which shows an accuracy of 91.96%, while a suboptimal result (98.2%) is achieved in AS3.
Table 4 aims to compare the results obtained by different HAR methods on MSR Action3D considering the cross-subject evaluation protocol and averaging the results on AS1, AS2, and AS3. Only the works in which the use of cross-subject test with actors 1-3-5-7-9 for training and the rest for testing is clearly stated are included in the table.
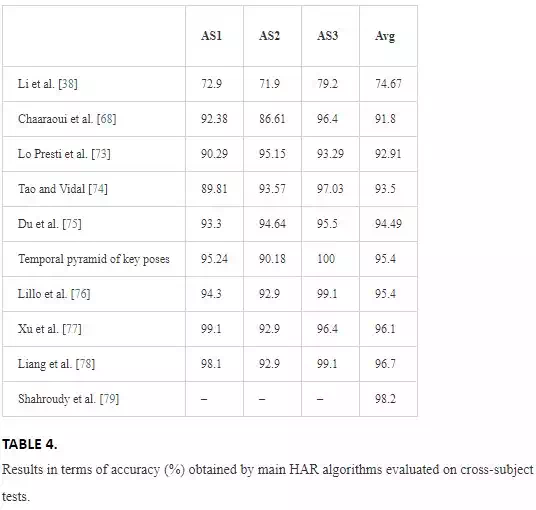
Some recently published works outperform the performance achieved by the method based on temporal pyramid of key poses. Lillo et al. proposed an activity recognition method based on three levels of abstraction. The first level is dedicated to learning the most representative primitives related to body motion. The poses are combined to compose atomic actions at the mid-level, and more atomic actions are combined to create more complex activities at the top-level. As input data, the aforementioned proposal exploits angles and planes from segments extracted from joint coordinates, adding also histograms of optical flow calculated from RGB patches centered at the joint locations. Xu et al. proposed the adoption of depth motion map (DMM), which is computed from the differences among consecutive maps, to describe the dynamic feature of an action. In addition to this method, the depth static model (DSM) can describe the static feature of an action. The so-called TPDM-SPHOG descriptor encodes DMMs and DSM represented by a temporal pyramid and histogram of oriented gradient (HOG) extracted using a spatial pyramid. DMM and multiscale HOG descriptors are also exploited by Liang et al., and they are combined with local space-time auto-correlation of gradients (STACOG), which compensates the loss of temporal information. l2-regularized collaborative representation classification (CRC) is adopted to take as inputs for the proposed descriptors and classify the actions. In Ref., a joint sparse regression learning method, which models each action as a combination of multimodal features from body parts, is proposed. In fact, each skeleton is separated into a number of parts and different features, related to the movement and local depth information, are extracted from each part. A small number of active parts for each action class are selected through group sparsity regularization. A hierarchical mixed norm, which includes three levels of regularization over learning weights, is integrated into the learning and selection framework.
The comparison of the algorithm based on temporal pyramid of key poses to other approaches achieving higher accuracies on MSR Action3D allows to conclude that all the considered works exploit not only skeleton data but also RGB or depth information. One approach is based on the extraction of the most important postures considering skeleton joints and RGB data, DMM and HOG descriptors calculated from depth data are exploited by more papers, and a heterogeneous set of depth and skeleton-based features has been considered in Ref.
Conclusion
Human action recognition performed exploiting data collected by RGB-D devices has been an active research field and many researchers are developing algorithms exploiting the properties and characteristics of depth sensors. The main advantages in using this technology include unobtrusiveness and privacy preservation, differently from video-based solutions; additionally, it does not extract movements from interaction with objects, as environmental sensors do, and it does not require the subject to wear any device, differently from systems based on wearable technologies.
Among the HAR algorithms based on RGB-D data, the chapter provided a detailed discussion of a method exploiting a temporal pyramid of key poses that has been able to achieve state-of-the-art results on the well-known MSR Action3D dataset.