The operating system on your laptop is running tens or hundreds of processes concurrently. It gives each process just the right amount of resources that it needs (RAM, CPU, IO). It isolates them in their own virtual address space, locks them down to a set of predefined permissions, allows them to inter-communicate, and allow you, the user, to safely monitor and control them. The operating system abstracts away the hardware layer (writing to a flash drive is the same as writing to a hard drive) and it doesn’t care what programming language or technology stack you used to write those apps – it just runs them, smoothly and consistently.
As machine learning penetrates the enterprise, companies will soon find themselves productionizing more and more models and at a faster clip. Deployment efficiency, resource scaling, monitoring and auditing will start to become harder and more expensive to sustain over time. Data scientists from different corners of the company will each have their own set of preferred technology stacks (R, Python, Julia, Tensorflow, Caffe, deeplearning4j, H2O, etc.) and data center strategies will shift from one cloud to hybrid. Running, scaling, and monitoring heterogeneous models in a cloud-agnostic way is a responsibility analogous to an operating system – that’s what we want to talk about.
At Algorithmia.com, we run 3,500+ algorithms (each has multiple versions, taking the figure up to 40k+ unique REST API endpoints). Any API endpoint can be called anywhere from once a day to a burst of 1,000+ times a second, with a completely no-devops experience. Those algorithms are written in any of the eight programming languages we support today, can be CPU or GPU based, will run on any cloud, can read and write to any data source (S3, Dropbox, etc.) and operate with a latency of ~15ms on standard hardware.
We see Algorithmia.com as our version of an OS for AI and this post will share some of our thinking.
· Training vs. Inference
· Serverless FTW
· Kernels and Shells
· Kernel #1 Elastic Scale
· Kernel #2 Runtime Abstraction
· Kernel #3 Cloud Abstraction
· Summary
Machine and deep learning is made up of two distinct phases: training and inference. The former is about building the model, and the latter is about running it in production.

Training a model is an iterative process that is very framework dependent. Some machine learning engineers will use Tensorflow on GPUs, others will use scikit-learn on CPUs, and every training environment is a snowflake. This is analogous to building an app, where an app developer has a carefully put-together development toolchain and libraries, constantly compiling and testing their code. Training requires a long compute cycle (hours to days), is usually fixed load input (meaning you don’t need to scale from one machine to X machines in response to a trigger), and is ideally a stateful process whereby the data scientist will need to repeatedly save progress of their training, such as neural network checkpoints.
Inference on the other hand is about running that model at scale to multiple users. When running numerous models concurrently, each written in different frameworks and languages, that’s when it becomes analogous to an operating system. The OS will be responsible for scheduling jobs, sharing resources, and monitoring of those jobs. A “job” is an inference transaction, and unlike in the case of training, requires a short burst of compute cycle (similar to an SQL query), elastic load (machines need to increase/decrease in proportion to inference demand), and is stateless, where the result of a previous transaction does not impact the result of the next transaction.
We will be focusing on the Inference side of the equation.
We’ll be using serverless computing for our operating system, so let’s take a moment to explain why serverless architecture makes sense for AI inference.
As we explained in the previous section, machine learning inference requires a short compute burst. This means a server that is serving a model as a REST API will be idle. When it receives a request, say, to classify an image, it will burst CPU/GPU utilization for a short period of time, return the result, then resume to being idle. This process is similar a database server that is idle until it receives an SQL query.
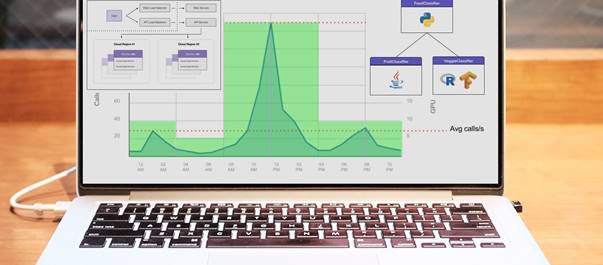
Because of this requirement, AI inference is a perfect fit for serverless computing. Serverless architecture has an obvious scaling advantage and an economic advantage. For example, let’s say you’ve built an app called “SeeFood” which classifies images as Hotdog and Not Hotdog. Your app goes viral and is now on the top charts. Here’s how your daily app usage might look like.

“SeeFood” Daily App Usage. It’s very popular during lunch time.
Y axis is “calls per second”. X axis is “hour of the day”.
In this fictional scenario, if we were to use traditional (fixed scale) architecture, then we’d be paying for 40 machines per day. This is the area highlighted in green below. With standard cloud pricing, this might cost us around $648 * 40 = $25,920 per month.

Traditional Architecture – Design for Maximum
40 machines 24 hours. $648 * 40 = $25,920 per month
If instead we used a auto-scaling architecture (where we would add or remove machines every hour) then we’d be paying for on average 19 machines per day. This is the area highlighted in green below. That’s a total of $648 * 19 = $12,312 per month.

Autoscale Architecture – Design for Local Maximum
19 machines 24 hours. $648 * 40 = $12,312 per month
And finally, if we use a serverless architecture, then we’d be paying for (theoretically) exactly the amount that we use, and not paying for the idle time. This is all the blue area in the chart below. The cost in this fictional scenario is tricky to calculate – it comes down to an average of of 21 calls / sec, or equivalent of 6 machines. That’s $648 * 6 = $3,888 per month.

Serverless Architecture – Design for Minimum
Avg. of 21 calls / sec, or equivalent of 6 machines. $648 * 6 = $3,888 per month
In this (fictional) scenario, our cloud computing cost went from ~$26k to ~$4k. That’s a great reason to use Serverless Computing, in addition to other advantages such as simpler development (functions are encapsulated as atomic services), lower latency (when used with edge computing), and rolling deployment capabilities.
Building a serverless architecture from scratch is not a particularly difficult feat, especially with recent devops advancements. Projects like Kubernetes and Docker will greatly simplify the distribution, scaling, and healing requirements for a function-as-a-service architecture.
 Example FaaS Architecture
Example FaaS Architecture
An API call is routed to an API Server then routed to a warmed up Docker container.
The container loads and executes the code just-in-time.
At this stage, we have table stakes for a serverless architecture. Building this and stopping there is the equivalent of using AWS Lambda. However for our system to be more valuable to AI workflows, we need to accommodate additional requirements such as GPU memory management, composability, cloud abstraction, instrumentation, and versioning to name a few.
Anything we build on top of our function-as-a-service platform is what really defines our operating system, and that’s what we’ll talk about next.
Similar to how an operating system is made up of Kernel, Shell, and Services, our operating system will consist of those components as well.

The Shell is the part that the user interacts with, such as the website or API endpoint. Services are pluggable components of our operating system, such as authentication and reporting. The last layer, the Kernel, is what really defines our operating system. This is the layer we will focus on for the rest of the post.
Our kernel is made up of three major components: elastic scaling, runtime abstraction, and cloud abstraction. Let’s explore each of those components in detail.
If we know that Algorithm #A will always call Algorithm #B, how can we use that knowledge to our advantage? That’s the intelligent part of scaling up on demand.
Composability is a very common pattern in the world of machine learning and data science. A data pipeline will typically consist of pre-processing stage(s), processing, and post-processing. In this case the pipeline is the composition of different functions that make up the pipeline. Composability is also found in ensembles, where the data scientist runs the model through different models and then synthesize the final score.
Here’s an example: let’s say our “SeeFood” takes a photo of a fruits or vegetables and then return the name of the fruit or the vegetable. Instead of building a single classifier for all food and vegetables, it’s common to break it down to three classifiers, like so.

In this case, we know that the model on the top (“Fruit or Veggie Classifier”) will always call either “Fruit Classifier” or “Veggie Classifier”. How do we use this to our advantage? One way is to instrument all the resources, keeping track of what CPU level, memory level, and IO level each model consumes. Our orchestrator can be designed to use this information when stack those jobs, in a way that reduces network or increase server utilization (fitting more models in a single server).

The second component in our kernel is runtime abstraction. In machine learning and data science workflows, it’s common that we build a classifier with a certain stack (say R, Tensorflow over GPUs) and have pre-processing or adjacent model running on a different stack (maybe Python, scikit-learn over CPUs).

Our operating system must abstract away those details and enable seamless interoperability between functions and models. For this, we use REST APIs and exchange data using JSON or equivalent universal data representation. If the data was too large, we pass around the URI to the data source instead of the actual JSON blob.
These day we do not expect programmers to be devops. More so, we do not expect data scientists to understand all the intricate details of different cloud vendors. Dealing with different data sources is a great example of such abstraction.
Imagine a scenario where a data scientist creates a model that classifies images. Consumers of that model might be three different personas: (a) backend production engineers might be using S3, (b) fellow data scientists might be using Hadoop, and (3) BI users in a different org might be using Dropbox. Asking the author of that model to build a data connector for each of those sources (and maintain it for new data sources in the future) is a distraction from their job. Instead, our operating system can offer a Data Adapter API that reads and writes from different data sources.

In the above code shows two examples: reading data without
abstraction, and reading data with abstraction.
In the first block, not having storage abstraction requires us to write a connector for each data source (in this case S3) and hard code it in our model. In the second block, we use the Data Adapter API which takes in a URI to a data source and automatically injects the right data connector. Those URIs can point to S3, Azure Blob, HDFS, Dropbox, or anything else.
Our operating system so far is auto-scaling, composable, self-optimizing, and cloud-agnostic. Monitoring your hundreds or thousands of models is also a critical requirement. There is however room for one more thing: Discoverability.
Discoverability is the ability to find models and functions created by:
Operating systems are not the product, they are the platform. If you examine how operating systems evolved over time, we went from punched cards, to machine language, to assemblers, and so on, slowly climbing the ladder of Abstraction. Abstraction is about looking at things as modular components, encouraging reuse, and making advanced workflows more accessible. That’s why the latest wave of operating systems (the likes iOS and Android) came with built-in App Stores, to encourage this view of an OS.

For the same reasons, our operating system must place much emphasis on Discoverability and Reusability. That’s why at Algorithmia we created CODEX, our on-prem operating system for AI, and Algorithmia.com, our app store for algorithms, functions and models. We help companies make their algorithms discoverable to every corner of their organization, and at the same time, we give those companies (and indie developers) access to the best third-party algorithms via Algorithmia.com.