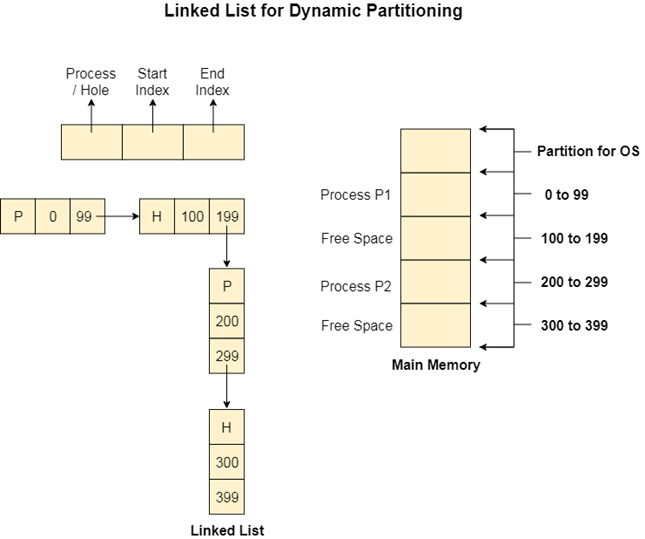
The better and the most popular approach to keep track the free or filled partitions is using Linked List.
In this approach, the Operating system maintains a linked list where each node represents each partition. Every node has three fields.
If a partition is freed at some point of time then that partition will be merged with its adjacent free partition without doing any extra effort.
There are some points which need to be focused while using this approach.
There are various algorithms which are implemented by the Operating System in order to find out the holes in the linked list and allocate them to the processes.
The explanation about each of the algorithm is given below.
1. First Fit Algorithm
First Fit algorithm scans the linked list and whenever it finds the first big enough hole to store a process, it stops scanning and load the process into that hole. This procedure produces two partitions. Out of them, one partition will be a hole while the other partition will store the process.
First Fit algorithm maintains the linked list according to the increasing order of starting index. This is the simplest to implement among all the algorithms and produces bigger holes as compare to the other algorithms.
2. Next Fit Algorithm
Next Fit algorithm is similar to First Fit algorithm except the fact that, Next fit scans the linked list from the node where it previously allocated a hole.
Next fit doesn't scan the whole list, it starts scanning the list from the next node. The idea behind the next fit is the fact that the list has been scanned once therefore the probability of finding the hole is larger in the remaining part of the list.
Experiments over the algorithm have shown that the next fit is not better then the first fit. So, it is not being used these days in most of the cases.
3. Best Fit Algorithm
The Best Fit algorithm tries to find out the smallest hole possible in the list that can accommodate the size requirement of the process.
Using Best Fit has some disadvantages.
· It is slower because it scans the entire list every time and tries to find out the smallest hole which can satisfy the requirement the process.
· Due to the fact that the difference between the whole size and the process size is very small, the holes produced will be as small as it cannot be used to load any process and therefore it remains useless.
Despite of the fact that the name of the algorithm is best fit, It is not the best algorithm among all.
Worst Fit Algorithm
The worst fit algorithm scans the entire list every time and tries to find out the biggest hole in the list which can fulfill the requirement of the process.
Despite of the fact that this algorithm produces the larger holes to load the other processes, this is not the better approach due to the fact that it is slower because it searches the entire list every time again and again.
5. Quick Fit Algorithm
The quick fit algorithm suggests-maintaining the different lists of frequently used sizes. Although, it is not practically suggestible because the procedure takes so much time to create the different lists and then expending the holes to load a process.
The first fit algorithm is the best algorithm among all because
· It takes lesser time compare to the other algorithms.
· It produces bigger holes that can be used to load other processes later on.
· It is easiest to implement.