Accelerating Simulation Run Time with GPUs
As engineers, we're constantly faced with technical problems that require us to push the limits of what was previously thought to be possible. The continued development of simulation tools like FEA and CFD has played a key role in aiding us to advance new technologies and bridge the gap between scientific knowledge and practical solutions. A natural consequence of the expanding role and capabilities of simulation is the growth in both the size and complexity of our models. Analysts today build models that capture more geometric detail; include multiple, coupled physics (i.e. fluid-structure interaction); and investigate parametric variation of their design. Unfortunately one thing that hasn't changed is the pressure from your boss or FEA orCFD consuting client to deliver results yesterday!
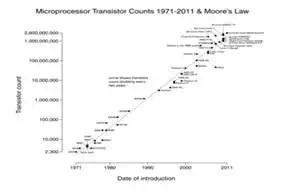
So what is an engineer to do? In the past, growth in model size has been accompanied by an increase in CPU power and speed with every new generation of chip. Need to build a bigger model? Just wait for the next generation of CPU's to be released and harness the extra horsepower! In recent years, however, the rate at which processor speeds have increased has begun to slow due to the associated increase in power consumption and limits on ever-shrinking transistor sizes. To continually increase computing capabilities and keep pace with Moore's law, CPU manufacturers and software developers have turned to parallelism - taking a divide and conquer approach to heavy computing by using multiple processors to share the workload. This presents a new paradigm for software development, requiring numerical algorithms to be rewritten and optimized to take advantage of parallelization. In this vein, many scientific computing applications are now exploring the use of Graphics Processing Units (GPU's), whose capabilites have undergone explosive growth due to demand for more complex computer graphics and rendering.
|
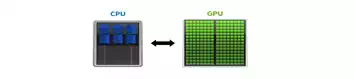
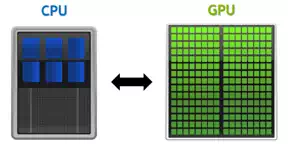
The key difference between a CPU and a GPU is the number of processing cores. Whereas a typical workstation may have dual CPU's with 4 to 8 cores each that are adept at performing complex serial calculations; a single GPU can have hundreds or even thousands of simpler processing cores designed to perform calculations simultaneously. GPU's open the door to a world of massively parallel computing that has previously required access to a supercomputer or cluster of workstations.
|
For scientific computing purposes, GPUs typically work in concert with a machines CPU. For example, the ANSYS Mechanical Sparse solver uses the CPU to assemble the linear system of equations, and then offloads the more computationally expensive factorization and solution phase to the GPU. This allows massive parallelization of the intense number crunching required by the solver. Recent benchmarks have shown 2-4x speed-up in solution time when using a single GPU - welcome news to anyone who's had an FEA or CFD consulting client breathing down their neck for results!
As numerical algorithms are optimized for massive parallelization and expanded to include more applications, expect GPUs to become more and more prevalent in simulation workflows. For an example of the use of GPUs in simulation today, see this white paper on the design of 3-D glasses.