Database
Database is a repository or collection of logically related, and similar data. Database stores similar kind of data that is organized in a manner that the information can be derived from it, modified, data added, or deleted to it, and used when needed. Some examples of databases in real life situations are: dictionary—a database of words organized alphabetically along with their meaning, telephone directory—a database of telephone numbers and addresses organized by the last name of people, railway timetable— a database of trains organized by train names, and, companies listed on Stock Exchange organized by names alphabetically.
A database is defined as—(1) a collection, or repository of data, (2) having an organized structure, and (3) for a specific purpose. A database stores information, which is useful to an organization. It contains data based on the kind of application for which it is required. For example, an airline database may contain data about the airplane, the routes, airline reservation, airline schedules etc.; a college database may contain data about the students, faculty, administrative staff, courses, results etc.; a database for manufacturing application may contain data about the production, inventory, supply chain, orders, sales etc.; and a student database may contain data about students, like student names, student course etc.
File-Oriented Approach and Database Approach
In the early days, data was stored in files. For an application, multiple files are required to be created. Each file stores and maintains its own related data. For example, a student information system would include files like student profile, student course, student result, student fees etc. The application is built on top of the file system. However, there are many drawbacks of using the file system, as discussed below—
· Data redundancy means storing the same data at multiple locations. In an application, a file may have fields that are common to more than one file. The data for these common fields is thus replicated in all the files having these fields. This results in data redundancy, as more than one file has the same data values stored in them. For example, student name and student course may be stored in two files—“student profile” and “student fees”.
· Data inconsistency means having different data values for the common fields in different files. During the updating process, the common fields may not get updated in all the files. This may result in different data values for the common fields in different files. For example, a student having different home address in two different files. Data redundancy provides opportunity for data inconsistency. Figure shows data redundancy, and data inconsistency in two files.
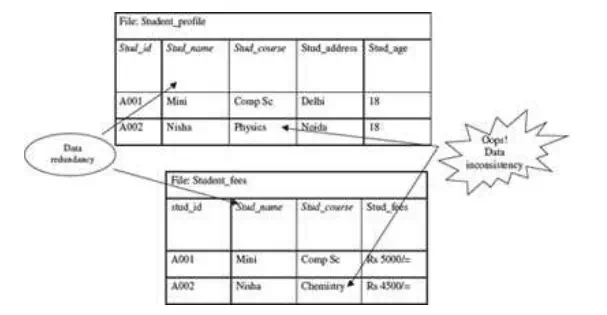
Data inconsistency and data redundancy
· The files in which the data is stored can have different file formats. This results in difficulty in accessing the data from the files since different methods are required for accessing the data from the files having different formats.
· In a file system, the constraints of the system (for example, student age >17) become part of the program code. Adding new constraints or changing an existing one becomes difficult.
· The files can be accessed concurrently by multiple users. Uncontrolled concurrent access may lead to inconsistency and security problems. For example, two users may try to update the data in a file at the same time.
Database approach provides solutions for handling the problems of the file system approach. The emergence of database approach has resulted in a paradigm shift, from each application defining and maintaining its own data (file-oriented approach)—to the data being defined and administered centrally (database approach). In the database approach, data is defined and stored centrally.