Evaluating the important parts
Once we’ve finished scanning our source text and identified our lexemes, we’ll need to do something with our lexeme “words”. This is the evaluation step of lexical analysis, which is often referred to in complier design as the process of lexing or tokenizing our input.

What does it mean to evaluate the scanned code?
When we evaluate our scanned code, all we’re really doing is taking a closer look at each of the lexemes that our scanner generated. Our compiler will need to look at each lexeme word and decide what kind of word it is. The process of determining what kind of lexeme each “word” in our text is how our compiler turns each individual lexeme into a token, thereby tokenizing our input string.
We first encountered tokens back when we were learning
about parse trees. Tokens are special symbols that are at the crux of each
programming language. Tokens, such as (, ), +, -,
if, else, then, all help a compiler understand how
different parts of an expression and various elements relate to one another.
The parser, which is central to the syntax analysis phase, depends on receiving
tokens from somewhere and then turns those
tokens into a parse tree.

Tokens: a definition.
Well, guess what? We’ve finally figured out the “somewhere”! As it turns out, the tokens that get sent to the parser are generated in the lexical analysis phase by the tokenizer, also called the lexer.
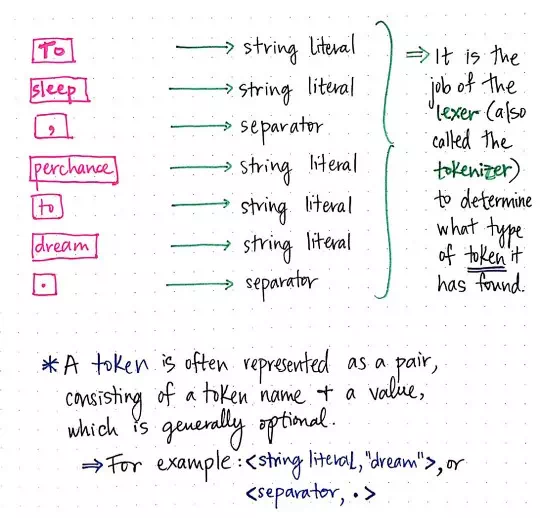
Tokenizing our Shakespearean sentence!
So what exactly does a token look like? A token is fairly simple, and is usually represented as a pair, consisting of a token name, and some value (which is optional).
For example, if we tokenize our Shakespearean string,
we’d end up with tokens that would be mostly string literals and separators. We
could represent the lexeme “dream” as
a token like so: <string literal,
"dream">. In a similar vein, we could represent the
lexeme . as the token, <separator, .>.
We’ll notice that each of these tokens aren’t modifying the lexeme at all — they’re simply adding additional information to them. A token is lexeme or lexical unit with more detail; specifically, the added detail tells us what category of token (what type of “word”) we’re dealing with.
Now that we’ve tokenized our Shakespearean sentence, we can see that there’s not all that much variety in the types of tokens in our source file. Our sentence only had strings and punctuation in it — but that’s just the tip of the token iceberg! There are plenty of other types of “words” that a lexeme could be categorized into.
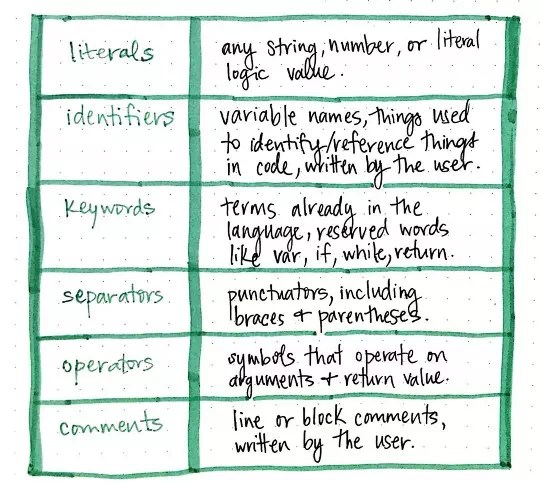
Common forms of tokens found within our source code.
The table shown here illustrates some of the most common
tokens that our compiler would see when reading a source file in pretty much
any programming language. We saw examples of literals, which can be any string, number, or
logic/boolean value, as well as separators, which
are any type of punctuation, including braces ({}) and parentheses (()).
However, there are also keywords, which are terms that are reserved in the
language (such as if, var, while, return), as well as operators, which operate on arguments and return some
value ( +, -, x, /). We could also encounter lexemes that could be
tokenized as identifiers, which
are usually variable names or things written by the user/programmer to
reference something else, as well as comments, which
could be line or block comments written by the user.
Our original sentence only showed us two examples of
tokens. Let’s rewrite our sentence to instead read: var toSleep = "to dream";. How might
our compiler lex this version of Shakespeare?
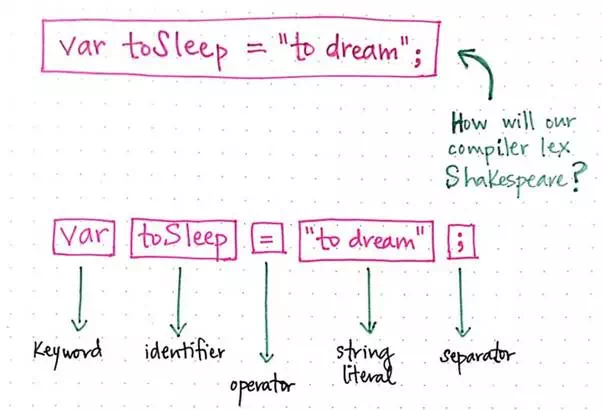
How will our lexer tokenize this sentence?
Here, we’ll see that we have a larger variety of tokens.
We have a keyword in var, where we’re declaring a variable, and an identifier, toSleep, which
is the way that we’re naming our variable, or referencing the value to come.
Next is our =, which is an operator token, followed by the string
literal "to dream". Our
statement ends with a ; separator,
indicating the end of a line, and delimitating whitespace.
An important thing to note about the tokenization process is that we’re neither tokenizing any whitespace (spaces, newlines, tabs, end of line, etc.), nor passing it on to the parser. Remember that only the tokens are given to the parser and will end up in the parse tree.
It’s also worth mentioning that different languages will
have different characters that constitute as whitespace. For example, in some
situations, the Python programming language uses indentation — including
tabs and spaces — in order to indicate how the scope of
a function changes. So, the Python compiler’s
tokenizer needs to be aware of the fact that, in certain situations, a tab or space actually
does need to be tokenized as a word, because it actually does need
to be passed to the parser!

Constraints of the lexer vs the scanner.
This aspect of the tokenizer is a good way of contrasting how a lexer/tokenizer is different from a scanner. While a scanner is ignorant, and only knows how to break up a text into its smaller possible parts (its “words”), a lexer/tokenizer is much more aware and more precise in comparison.
The tokenizer needs to know the intricacies and
specifications of the language that is being compiled. If tabs are important, it needs to know that; if newlinescan have certain meanings in the language
being compiled, the tokenizer needs to be aware of those details. On the other
hand, the scanner doesn’t even know what the words that it divides even are,
much less what they mean.
The scanner of a complier is far more language-agnostic, while a tokenizer must be language-specific by definition.
These two parts of the lexical analysis process go hand-in-hand, and they are central to the first phase of the compilation process. Of course, different compliers are designed in their own unique ways. Some compilers do the step of scanning and tokenizing in one single process and as a single program, while others will split them up into different classes, in which case the tokenizer will call out to the scanner class when it is run.
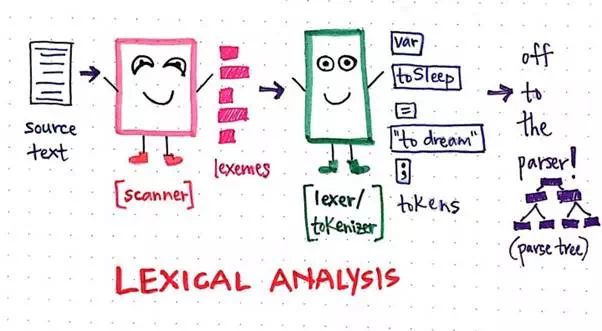
Lexical analysis: a quick visual summary!
In either case, the step of lexical analysis is super important to compilation, because the syntax analysis phase directly depends upon it. And even though each part of the compiler has its own specific roles, they lean on one another and depend on each other — just like good friends always do.