Reading Code Right, With Some Help From The Lexer

Software is all about logic. Programming has garnered a reputation of being a field that is heavy on the math and crazy equations. And computer science seems to be at the crux of this misconception.
Sure, there is some math and there are some formulas — but none of us actually need to have PhDs in calculus in order for us to understand how our machines work! In fact, a lot of the rules and paradigms that we learn in the process of writing code are the same rules and paradigms that apply to complex computer science concepts. And sometimes, those ideas actually stem from computer science, and we just didn’t ever know it.
Regardless of what programming language we use, when most of us write our code, we aim to encapsulate distinct things into classes, objects, or methods, intentionally separating out what different parts of our code are concerned with. In other words, we know that it’s generally good things to divide up our code so that one class, object, or method is only concerned with and responsible for one single thing. If we didn’t do this, things could get super messy and intertwined into a mess of a web. Sometimes this still happens, even with separation of concerns.
As it turns out, even the inner workings of our computers follow very similar design paradigms. Our compiler, for example, has different parts to it, and each part is responsible for handling one specific part of the compilation process. We encountered a little bit of this last week, when we learned about the parser, which is responsible for creating parse trees. But the parser can’t possibly be tasked with everything.
The parser needs some help from its buddies, and it’s finally time for us to learn who they are!
Phasing into compilers
When we learned about parsing recently, we dipped our toes into grammar, syntax, and how the compiler reacts and responds to those things within a programming language. But we never really highlighted what exactly a compiler is! As we get into the inner workings of the compilation process, we’re going to be learning a lot about compiler design, so it’s vital for us to understand what exactly we’re talking about here.
Compilers can sound kind of scary, but their jobs are actually not too complex to understand — particularly when we break the different parts of a complier down into bite-sized parts.
But first, let’s start with the simplest definition possible. A compiler is a program that reads our code (or any code, in any programming language), and translates it into another language.

The compiler: a definition.
Generally speaking, a compiler is really only ever going to translate code from a high-level language into a lower level language. The lower level languages that a compiler translates code into is often referred to as assembly code, machine code, or object code. It’s worth mentioning that most programmers aren’t really dealing with or writing any machine code; rather, we depend on the compiler to take our programs and translate them into machine code, which is what our computer will run as an executable program.
We can think of compilers as the middleman between us, the programmers, and our computers, which can only run executable programs in lower level languages.
The compiler does the work of translating what we want to happen in a way that is understandable and executable by our machines.
Without the compiler, we’d be forced to communicate with our computers by writing machine code, which is incredibly unreadable and hard to decipher. Machine code can often just look like a bunch of 0’s and 1’s to the human eye — it’s all binary, remember? — which makes it super hard to read, write, and debug. The compiler abstracted away machine code for us as programmers, because it made it very easy for us to not think about machine code and write programs using far more elegant, clear, and easy-to-read languages.
We’ll continue to unpack more and more about the mysterious compiler over the next few weeks, which will hopefully make it less of an enigma in the process. But for now, let’s get back to the question at hand: what are the simplest possible parts of a compiler?
Each compiler, no matter how it might be designed, has distinct phases. These phases are how we can distinguish the unique parts of the compiler.

Syntax analysis: phase one of a compiler
We’ve already encountered one of the phases in our compilation adventures when we recently learned about the parser and parse trees. We know that parsing is the process of taking some input and building a parse tree out of it, which is sometimes referred to as the act of parsing. As it turns out, the work of parsing is specific to a phase in the compilation process called syntax analysis.
However, the parser doesn’t just build a parse tree out of thin air. It has some help! We’ll recall that the parser is given some tokens (also called terminals), and it builds a parse tree from those tokens. But where does it get those tokens from? Lucky for the parser, it doesn’t have to operate in a vacuum; instead, it has some help.
This brings us to another phase of the compilation process, one that comes before the syntax analysis phase: the lexical analysis phase.
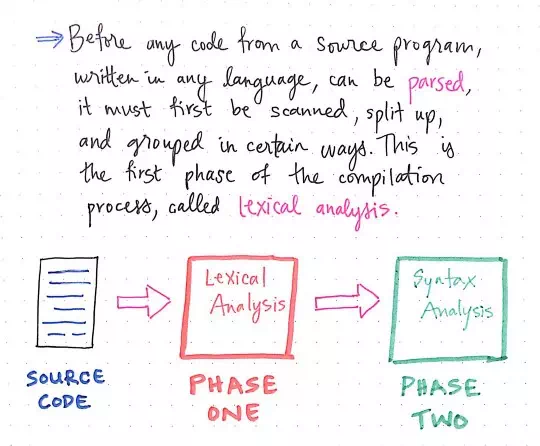
The initial phases of a compiler
The term “lexical” refers to the meaning of a word in isolation from the sentence containing it, and regardless of its grammatical context. If we try to guess our own meaning based solely upon this definition, we could posit that the lexical analysis phase has to do with the individual words/terms in the program themselves, and nothing to do with the grammar or the meaning of the sentence that contains the words.
The lexical analysis phase is the first step in the compilation process. It doesn’t know or care about the grammar of a sentence or the meaning of a text or program; all it knows about are the meaning of the words themselves.
Lexical analysis must occur before any code from a source program can be parsed. Before it can be read by the parser, a program must first be scanned, split up, and grouped together in certain ways.
When we started looking at the syntax analysis phase last week, we learned that the parse tree is built by looking at individual parts of the sentence and breaking down expressions into simpler parts. But during the lexical analysis phase, the compiler doesn’t know or have access to these “individual parts”. Rather, it has to first identify and find them, and then do the work of splitting apart the text into individual pieces.
For example, when we read a sentence from Shakespeare
like To sleep, perchance to dream., we know
that the spaces and the punctuation are dividing up the “words” of a sentence.
This is, of course, because we’ve been trained to read a sentence, “lex” it,
and parse it for grammar.
But, to a compiler, that same sentence might look like
this the first time that it reads it: Tosleepperhachancetodream. When we
read this sentence, it’s a little harder for us
to determine what the actual “words” are! I’m sure our compiler feels the same
way.
So, how does our machine deal with this problem? Well, during the lexical analysis phase of the compilation process, it always does two important things: it scans the code, and then it evaluates it.

The two steps of the lexical analysis process!
The work of scanning and evaluating can sometimes be lumped together into one single program, or it could be two separate programs that depend on one another; it’s really just a question of how any one complier happened to be designed. The program within the compiler which is responsible for doing the work of scanning and evaluating is often referred to as the lexer or the tokenizer, and the entire lexical analysis phase is sometimes called the process of lexing or tokenizing.
To scan, perchance to read
The first of the two core steps in lexical analysis is scanning. We can think of scanning as the work of actually “reading” some input text. Remember that this input text could be a string, sentence, expression, or even an entire program! It doesn’t really matter, because, in this phase of the process, it’s just a giant blob of characters that doesn’t mean anything just yet, and is one contiguous chunk.
Let’s look at an example to see how exactly this
happens. We’ll use our original sentence, To sleep, perchance to dream., which is our source
text or source code. To our
compiler, this source text will be read as input text that looks like Tosleep,perchancetodream., which is just a string of characters that
has yet to be deciphered.
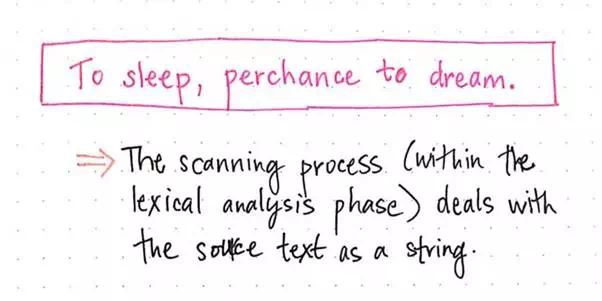
The scanning process, step 1.
The first thing our compiler has to do is actually divide up that blob of text into its smallest possible pieces, which will make it much easier to identify where the words in the blob of text actually are.
The simplest way of diving up a giant chunk of text is by reading it slowly and systematically, one character at a time. And this is exactly what the compiler does.
Oftentimes, the scanning process is handled by a separate program called the scanner, whose sole job it is to do the work of reading a source file/text, one character at a time. To our scanner, it doesn’t really matter how big our text is; all it will see when it “reads” our file is one character at a time.
Here’s what our Shakespearean sentence would be read as by our scanner:
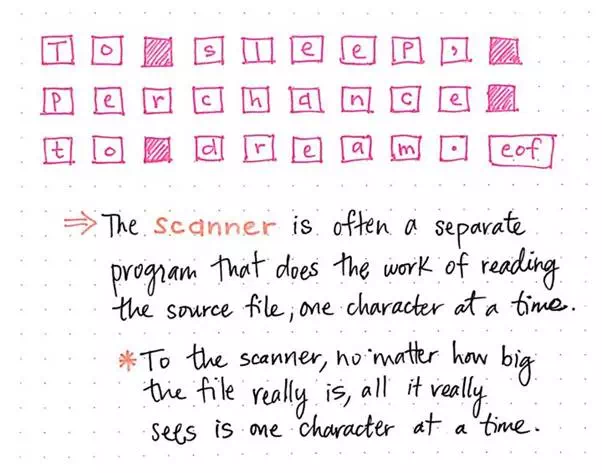
The scanning process, step 2.
We’ll notice that To sleep, perchance to dream. has been split into
individual characters by our scanner. Furthermore, even the spaces between the
words are being treated as characters, as is the punctuation in our sentence.
There’s also a character at the end of this sequence that is particularly
interesting: eof. This is the character “end
of file”, and it’s similar to tab, space, and newline. Since
our source text is just one single sentence, when our scanner gets to the end
of the file (in this case, the end of the sentence), it reads the end of file
and treats it as a character.
So, in actuality, when our scanner read our input text,
it interpreted it as individual characters which resulted in this: ["T", "o", space, "s", "l",
"e", "e", "p", ",", space,
"p", "e", "r", "c", "h",
"a", "n", "c", "e", space,
"t", "o", space, "d", "r",
"e", "a", "m", ".", eof].

The scanning process, step 3.
Now that our scanner has read and split up our source text into its smallest possible parts, it will have a much easier time of figuring out the “words” in our sentence.
Next, the scanner needs to look at its split up characters in order, and determine which characters are parts of a word, and which ones are not. For each character that the scanner reads, it marks the line and the position of where that character was found in the source text.
The image shown here illustrates this process for our Shakespearean sentence. We can see that our scanner is marking the line and the column for each character in our sentence. We can think of the line and column representation as a matrix or array of characters.
Recall that, since our file has only one single line in
it, everything lives at line 0.
However, as we work our way through the sentence, the column of each character
increments. It’s also worth mentioning that, since our scanner reads spaces, newlines, eof, and all punctuation as characters, those appear in our
character table, too!

The scanning process, step 4.
Once the source text has been scanned and marked, our
compiler is ready to turn these characters into words. Since the scanner knows
not just where the spaces, newlines, and eof in the file are, but also where they live in
relation to the other characters surrounding them, it can scan through the
characters, and divide the them into individual strings as necessary.
In our example, the scanner will look at the
characters T, then o, and then a space. When it
finds a space, it will divide To into
its own word — the simplest combination of
characters possible before the scanner encounters a space.
It’s a similar story for the next word that it finds,
which is sleep. However, in this scenario,
it reads s-l-e-e-p, and
then reads a ,, a punctuation mark. Since
this comma is flanked by a character (p) and
a space on either side, the
comma is, itself, considered to be a “word”.
Both the word sleep and
the punctuation symbol , are
called lexemes, which are substrings the source text. A
lexeme is a grouping of the smallest possible sequences of characters in our
source code. The lexemes of a source file are considered the individual “words”
of the file itself. Once our scanner finishes reading the single characters of
our file, it will return a set of lexemes that look like this: ["To", "sleep", ",",
"perchance", "to", "dream", "."].

The scanning process, step 5.
Notice how our scanner took a blob of text as its input, which it couldn’t initially read, and proceeded to scan it once character at a time, simultaneously reading and marking it the content. It then proceeded to divide the string into their smallest possible lexemes by using the spaces and punctuation between characters as delimiters.
However, despite all of this work, at this point in the lexical analysis phase, our scanner doesn’t know anything about these words. Sure, it split up the text into words of different shapes and sizes, but as far as what those words are the scanner has no idea! The words could be a literal string, or they could be a punctuation mark, or they could be something else entirely!
The scanner doesn’t know anything about the words themselves, or what “type” of word they are. It just knows where the words end and begin within the text itself.
This sets us up for the second phase of lexical analysis: evaluation. Once we’ve scanned our text and broken up the source code into individual lexeme units, we must evaluate the words that the scanner returned to us and figure out what types of words we’re dealing with — in particular, we must look for important words that mean something special in the language we’re trying to compile.