Leveling Up One’s Parsing Game With ASTs

Before I started on this journey of trying to learn computer science, there were certain terms and phrases that made me want to run the other direction.
But instead of running, I feigned knowledge of it, nodding along in conversations, pretending like I knew what someone was referencing even though the truth was that I had no idea and had actually stopped listening entirely when I heard That Super Scary Computer Science Term™. Throughout the course of this series, I’ve managed to cover a lot of ground and many of those terms have actually become a whole lot less scary!
There is one big one, though, that I’ve been avoiding for awhile. Up until now, whenever I had heard this term, I felt paralyzed. It has come up in casual conversation at meet ups and sometimes in conference talks. Every single time, I think of machines spinning and computers spitting out strings of code that are indecipherable except that everyone else around me can actually decipher them so it’s actually just me who doesn’t know what’s going on (whoops how did this happen?!).
Perhaps I’m not the only one who has felt that way. But, I suppose I should tell you what this term actually is, right? Well, get ready, because I’m referring to ever-elusive and seemingly confusing abstract syntax tree, or AST for short. After many years of being intimidated, I’m excited to finally stop being afraid of this term and truly understand what on earth it is.
It’s time to face the root of the abstract syntax tree head on — and level up our parsing game!
From concrete to abstract
Every good quest starts with a solid foundation, and our mission to demystify this structure should begin in the exact same way: with a definition, of course!
An abstract syntax tree (usually just referred to as an AST) is really nothing more than a simplified, condensed version of a parse tree. In the context of compiler design, the term “AST” is used interchangeably with syntax tree.

Abstract syntax tree: a definition
We often think about syntax trees (and how they are constructed) in comparison to their parse tree counterparts, which we’re already pretty familiar with. We know that parse trees are tree data structures that contain the grammatical structure of our code; in other words, they contain all the syntactic information that appears in a code “sentence”, and is derived directly from the grammar of the programming language itself.
A abstract syntax tree, on the other hand, ignores a significant amount of the syntatic information that a parse tree would otherwise contain.
By contrast, an AST only contains the information related to analyzing the source text, and skips any other extra content that is used while parsing the text.
This distinction starts to make a whole lot more sense if we focus in on the “abstractness” of an AST.
We’ll recall that a parse tree is an illustrated, pictorial version of the grammatical structure of a sentence. In other words, we can say that a parse tree represents exactly what an expression, sentence, or text looks like. It’s basically a direct translation of the text itself; we take the sentence and turn every little piece of it — from the punctuation to the expressions to the tokens — into a tree data structure. It reveals the concrete syntax of a text, which is why it is also referred to as a concrete syntax tree, or CST. We use the term concrete to describe this structure because it’s a grammatical copy of our code, token by token, in tree format.
But what makes something concrete versus abstract? Well, an abstract syntax tree doesn’t show us exactly what an expression looks like, the way that a parse tree does.

Concrete versus abstract syntax trees
Rather, an abstract syntax tree shows us the “important” bits — the things that we really care about, which give meaning to our code “sentence” itself. Syntax trees show us the significant pieces of an expression, or the abstracted syntax of our source text. Hence, in comparison to concrete syntax tress, these structures are are abstract representations of our code (and in some ways, less exact), which is exactly how they got their name.
Now that we understand the distinction between these two data structures and the different ways that they can represent our code, it’s worth asking the question: where does an abstract syntax tree fit into the compiler? First, let’s remind ourselves of everything that we know about the compilation process as we know it so far.
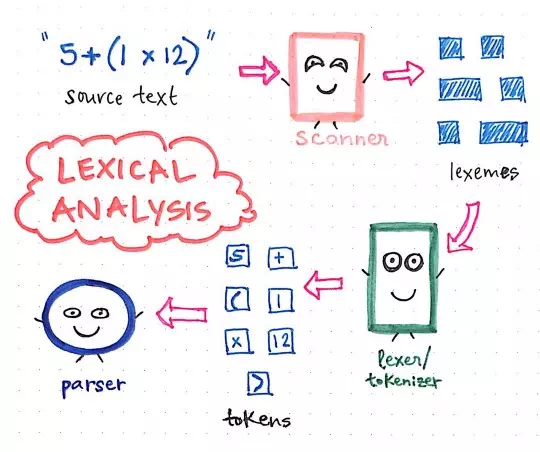
Revisiting the events leading up to parsing!
Let’s say we have a super short and sweet source text,
which looks like this: 5 + (1 x 12).
We’ll recall that the first thing that happens in the compilation process is the scanning of the text, a job performed by the scanner, which results in the text being broken up into its smallest possible parts, which are called lexemes. This part will be language agnostic, and we’ll end up with the stripped-out version of our source text.
Next, these very lexemes are passed on to the
lexer/tokenizer, which turns those small representations of our source text
into tokens, which will be specific to our language.
Our tokens will look something like this: [5, +, (, 1, x, 12, )]. The joint effort of the scanner and the
tokenizer make up the lexical analysis of
compilation.
Then, once our input has been tokenized, its resulting tokens are is passed along to our parser, which then takes the source text and builds a parse tree out of it. The illustration below exemplifies what our tokenized code looks like, in parse tree format.
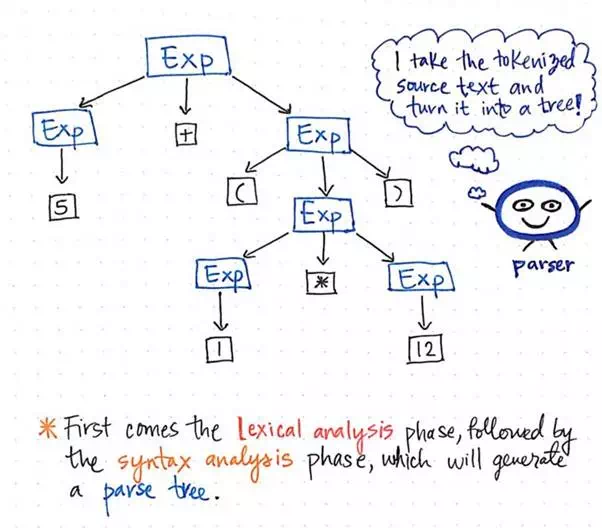
The syntax analysis phase generates the parse tree
The work of turning tokens into a parse tree is also called parsing, and is known as the syntax analysis phase. The syntax analysis phase depends directly on the lexical analysis phase; thus, lexical analysis must always come first in the compilation process, because our compiler’s parser can only do its job once the tokenizer does it’s job!
We can think of the parts of the compiler as good friends, who all depend on each other to make sure that our code is correctly transformed from a text or file into a parse tree.
But back to our original question: where does the abstract syntax tree fit into this friend group? Well, in order to answer that question, it helps to understand the need for an AST in the first place.