Distributed Mutual Exclusion
Process coordination in a multitasking OS
– Race condition: several processes access and manipulate the same data concurrently and the outcome of the execution depends on the particular order in which the access take place
– critical section: when one process is executing in a critical section, no other process is to be allowed to execute in its critical section
– Mutual exclusion: If a process is executing in its critical section, then no other processes can be executing in their critical sections
– Distributed mutual exclusion
– Provide critical region in a distributed environment
– message passing
– for example, locking files, locked daemon in UNIX (NFS is stateless, no file-locking at
– the NFS level) Algorithms for mutual exclusion
– Problem: an asynchronous system of N processes
– processes don't fail
– message delivery is reliable; not share variables
– only one critical region
– application-level protocol: enter(), resourceAccesses(), exit()
– Requirements for mutual exclusion
– Essential
– [ME1] safety: only one process at a time
– [ME2] liveness: eventually enter or exit
– Additional
– [ME3] happened-before ordering: ordering of enter() is the same as HB ordering
– Performance evaluation
– overhead and bandwidth consumption: # of messages sent
– client delay incurred by a process at entry and exit
– throughput measured by synchronization delay: delay between one's exit and next's entry
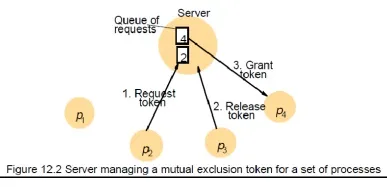
– A central server algorithm
– server keeps track of a token---permission to enter critical region
– a process requests the server for the token
– the server grants the token if it has the token
– a process can enter if it gets the token, otherwise waits
– when done, a process sends release and exits
– A central server algorithm: discussion
– Properties
– safety, why?
– liveness, why?
– HB ordering not guaranteed, why?
– Performance
– enter overhead: two messages (request and grant)
– enter delay: time between request and grant
– exit overhead: one message (release)
– exit delay: none
– synchronization delay: between release and grant
– centralized server is the bottleneck
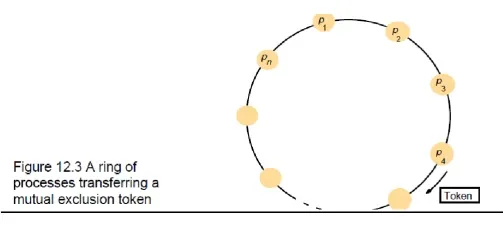
– ring-based algorithm
o Arrange processes in a logical ring to rotate a token
o Wait for the token if it requires to enter the critical section
o The ring could be unrelated to the physical configuration
o pi sends messages to p(i+1) mod N
o when a process requires to enter the critical section, waits for the token
o when a process holds the token
o If it requires to enter the critical section, it can enter
o when a process releases a token (exit), it sends to its neighbor
o If it doesn‘t, just immediately forwards the token to its neighbor
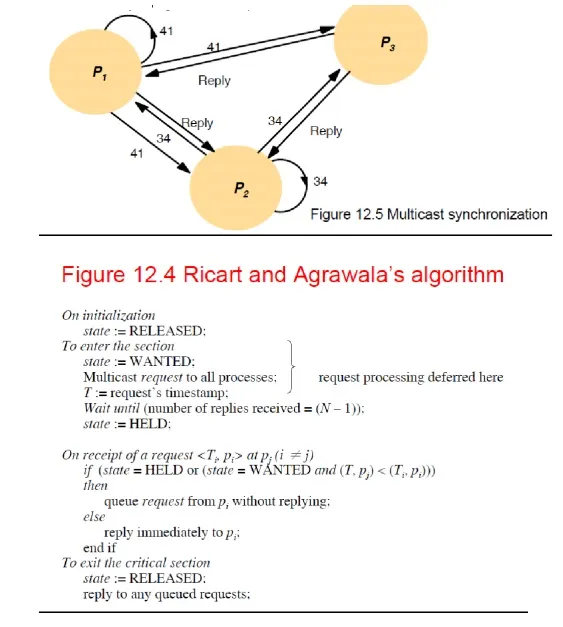
– An algorithm using multicast and logical clocks
– Multicast a request message for the token (Ricart and Agrawala [1981]
– enter only if all the other processes reply
– totally-ordered timestamps: <T, pi >
– Each process keeps a state: RELEASED, HELD, WANTED
– if all have state = RELEASED, all reply, a process can hold the token and enter
– if a process has state = HELD, doesn't reply until it exits
– if more than one process has state = WANTED, process with the lowest timestamp will get all
– N-1 replies first
– An algorithm using multicast: discussion
– Properties
– safety, why?
– liveness, why?
– HB ordering, why?
– Performance
– bandwidth consumption: no token keeps circulating
– entry overhead: 2(N-1), why? [with multicast support: 1 + (N -1) = N]
– entry delay: delay between request and getting all replies
– exit overhead: 0 to N-1 messages
– exit delay: none
o synchronization delay: delay for 1 message (one last reply from the previous holder)
– Maekawa‘s voting algorithm
– •Observation: not all peers to grant it access
– Only obtain permission from subsets, overlapped by any two processes
– •Maekawa‘s approach
– subsets Vi,Vj for process Pi, Pj
– Pi ∈ Vi, Pj ∈ Vj
– Vi ∩ Vj ≠ ∅ , there is at least one common member
– subset |Vi|=K, to be fair, each process should have the same size
– Pi cannot enter the critical section until it has received all K reply messages
– Choose a subset
– Simple way (2√N): place processes in a √N by √N matrix and let Vi be the union of the row and column containing Pi
– If P1, P2 and P3 concurrently request entry to the critical section, then its possible that each process has received one (itself) out of two replies, and none can proceed
– adapted and solved by [Saunders 1987]
