Grammars and Languages
· The types of grammars that exist are Noam Chomsky invented a hierarchy of grammars.
· The hierarchy consists of four main types of grammars.
· The simplest grammars are used to define regular languages.
· A regular language is one that can be described or understood by a finite state automaton. Such languages are very simplistic and allow sentences such as “aaaaabbbbbb.” Recall that a finite state automaton consists of a finite number of states, and rules that define how the automaton can transition from one state to another.
· A finite state automaton could be designed that defined the language that consisted of a string of one or more occurrences of the letter a. Hence, the following strings would be valid strings in this language:
ü aaa
ü a
ü aaaaaaaaaaaaaaaaa
· Regular languages are of interest to computer scientists, but are not of great interest to the field of natural language processing because they are not powerful enough to represent even simple formal languages, let alone the more complex natural languages.
· Sentences defined by a regular grammar are often known as regular expressions.
· The grammar that we defined above using rewrite rules is a context-free grammar.
· It is context free because it defines the grammar simply in terms of which word types can go together—it does not specify the way that words should agree with each. A stale dog climbs Mount Rushmore.
· It also, allows the following sentence, which is not grammatically correct: Chickens eats.
· A context-free grammar can have only at most one terminal symbol on the right-hand side of its rewrite rules.
· Rewrite rules for a context-sensitive grammar, in contrast, can have more than one terminal symbol on the right-hand side. This enables the grammar to specify number, case, tense, and gender agreement.
· Each context-sensitive rewrite rule must have at least as many symbols on the righthand side as it does on the left-hand side.
· Rewrite rules for context-sensitive grammars have the following form: A X B→A Y B which means that in the context of A and B, X can be rewritten as Y.
· Each of A, B, X, and Y can be either a terminal or a nonterminal symbol.
· Context-sensitive grammars are most usually used for natural language processing because they are powerful enough to define the kinds of grammars that natural
languages use. Unfortunately, they tend to involve a much larger number of rules and are a much less natural way to describe language, making them harder for human developers to design than context free grammars.
· The final class of grammars in Chomsky’s hierarchy consists of recursively enumerable grammars (also known as unrestricted grammars).
· A recursively enumerable grammar can define any language and has no restrictions on the structure of its rewrite rules. Such grammars are of interest to computer scientists but are not of great use in the study of natural language processing.
· Parsing: Syntactic Analysis
· As we have seen, morphologic analysis can be used to determine to which part of speech each word in a sentence belongs. We will now examine how this information is used to determine the syntactic structure of a sentence.
· This process, in which we convert a sentence into a tree that represents the sentence’s syntactic structure, is known as parsing.
· Parsing a sentence tells us whether it is a valid sentence, as defined by our grammar
· If a sentence is not a valid sentence, then it cannot be parsed. Parsing a sentence involves producing a tree, such as that shown in Fig 10.1, which shows the parse tree for the following sentence: The black cat crossed the road.
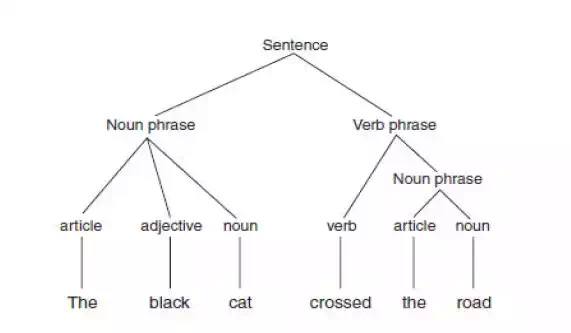
· This tree shows how the sentence is made up of a noun phrase and a verb phrase.
· The noun phrase consists of an article, an adjective, and a noun. The verb phrase consists of a verb and a further noun phrase, which in turn consists of an article and a noun.
· Parse trees can be built in a bottom-up fashion or in a top-down fashion.
· Building a parse tree from the top down involves starting from a sentence and determining which of the possible rewrites for Sentence can be applied to the sentence that is being parsed. Hence, in this case, Sentence would be rewritten using the following rule: Sentence→NounPhrase VerbPhrase
· Then the verb phrase and noun phrase would be broken down recursively in the same way, until only terminal symbols were left.
· When a parse tree is built from the top down, it is known as a derivation tree.
· To build a parse tree from the bottom up, the terminal symbols of the sentence are first replaced by their corresponding nonterminals (e.g., cat is replaced by noun), and then these nonterminals are combined to match the right-hand sides of rewrite rules.
· For example, the and road would be combined using the following rewrite rule: NounPhrase→Article Noun
Basic parsing techniques
· Transition Networks
· A transition network is a finite state automaton that is used to represent a part of a grammar.
· A transition network parser uses a number of these transition networks to represent its entire grammar.
· Each network represents one nonterminal symbol in the grammar. Hence, in the grammar for the English language, we would have one transition network for Sentence, one for Noun Phrase, one for Verb Phrase, one for Verb, and so on.
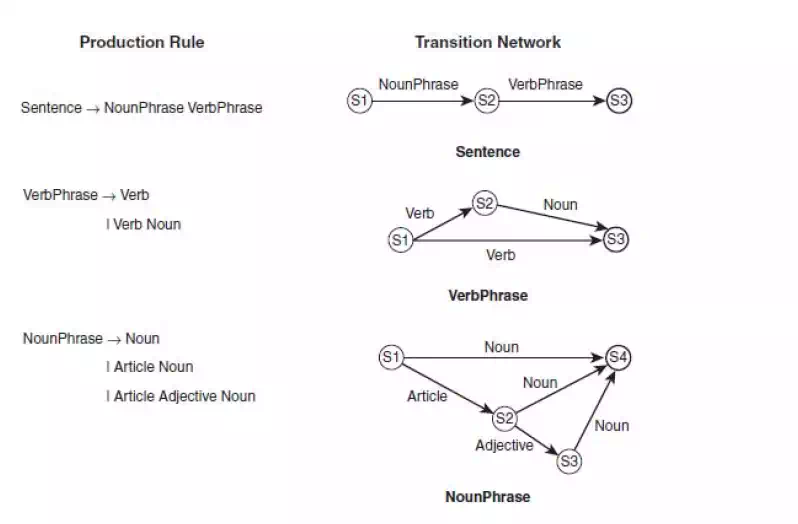
· Fig 10.2 shows the transition network equivalents for three production rules.
· In each transition network, S1 is the start state, and the accepting state, or final state, is denoted by a heavy border. When a phrase is applied to a transition
network, the first word is compared against one of the arcs leading from the first state.
· If this word matches one of those arcs, the network moves into the state to which that arc points. Hence, the first network shown in Fig 10.2, when presented with a Noun Phrase, will move from state S1 to state S2.
· If a phrase is presented to a transition network and no match is found from the current state, then that network cannot be used and another network must be
tried. Hence, when starting with the phrase the cat sat on the mat, none of the networks shown in Fig 10.2 will be used because they all have only nonterminal symbols, whereas all the symbols in the cat sat on the mat are terminal.Hence, we need further networks, such as the ones shown in Figure 10.2, which deal with terminal symbols.
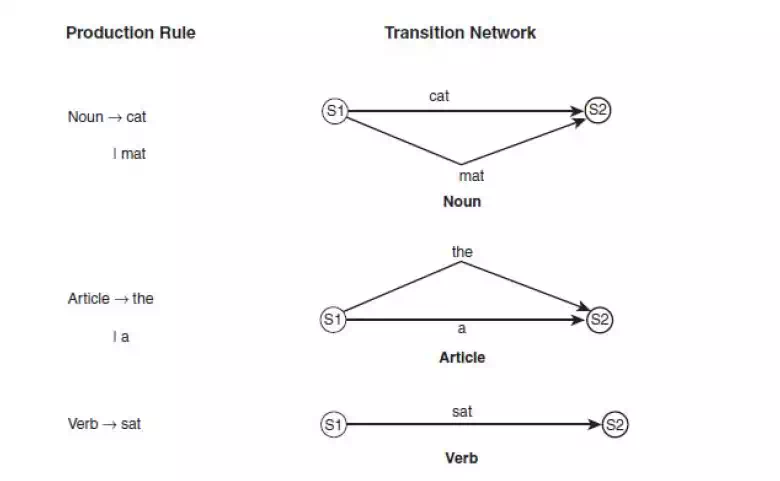
· Transition networks can be used to determine whether a sentence is grammatically correct, at least according to the rules of the grammar the networks represent.
· Parsing using transition networks involves exploring a search space of possible parses in a depth-first fashion.
· Let us examine the parse of the following simple sentence: A cat sat.
· We begin in state S1 in the Sentence transition network. To proceed, we must follow the arc that is labeled NounPhrase. We thus move out of the Sentence network and into the NounPhrase network.
· The first arc of the NounPhrase network is labeled Noun. We thus move into the Noun network. We now follow each of the arcs in the Noun network and discover that our first word, A, does not match any of them. Hence, we backtrack to the next arc in the NounPhrase network.
· This arc is labeled Article, so we move on to the Article transition network. Here, on examining the second label, we find that the first word is matched by the terminal symbol on this arc.
· We therefore consume the word, A, and move on to state S2 in the Article network. Because this is a success node, we are able to return to the NounPhrase network and move on to state S2 in this network. We now have an arc labeled Noun.
· As before, we move into the Noun network and find that our next word, cat, matches. We thus move to state S4 in the NounPhrase network. This is a success node, and so we move back to the Sentence network and repeat the process for the VerbPhrase arc.
· It is possible for a system to use transition networks to generate a derivation tree for a sentence, so that as well as determining whether the sentence is grammatically valid, it parses it fully to obtain further information by semantic analysis from the sentence.
· This can be done by simply having the system build up the tree by noting which arcs it successfully followed. When, for example, it successfully follows the NounPhrase arc in the Sentence network, the system generates a root node labeled Sentence and an arc leading from that node to a new node labeled NounPhrase.When the system follows the NounPhrase network and identifies an article and a noun, these are similarly added to the tree.
· In this way, the full parse tree for the sentence can be generated using transition networks. Parsing using transition networks is simple to understand, but is not necessarily as efficient or as effective as we might hope for. In particular, it does not pay any attention to potential ambiguities
or the need for words to agree with each other in case, gender, or number.
Augmented Transition Networks
· An augmented transition network, or ATN, is an extended version of a transition network.
· ATNs have the ability to apply tests to arcs, for example, to ensure agreement with number. Thus, an ATN for Sentence would be as shown in Figure 10.2, but the arc from node S2 to S3 would be conditional on the number of the verb being the same as the number for the noun.
· Hence, if the noun phrase were three dogs and the verb phrase were is blue, the ATN would not be able to follow the arc from node S2 to S3 because the number of the noun phrase (plural) does not match the number of the verb phrase (singular).
· In languages such as French, checks for gender would also be necessary. The conditions on the arcs are calculated by procedures that are attached to the arcs. The procedure attached to an arc is called when the network reaches that arc. These procedures, as well as carrying out checks on agreement, are able to form a parse tree from the sentence that is being analyzed.
Chart Parsing
· Parsing using transition networks is effective, but not the most efficient way to parse natural language. One problem can be seen in examining the following two sentences: 1. Have all the fish been fed? , Have all the fish.
· Clearly these are very different sentences—the first is a question, and thesecond is an instruction. In spite of this, the first three words of each sentence are the same.
· When a parser is examining one of these sentences, it is quite likely to have to backtrack to the beginning if it makes the wrong choice in the first case for the structure of the sentence. In longer sentences, this can be a much greater problem, particularly as it involves examining the same words more than once, without using the fact that the words have already been analyzed.

· Another method that is sometimes used for parsing natural language is chart parsing.
· In the worst case, chart parsing will parse a sentence of n words in O(n3) time. In many cases it will perform better than this and will parse most sentences in O(n2) or even O(n) time.
· In examining sentence 1 above, the chart parser would note that the words two children form a noun phrase. It would note this on its first pass through the sentence and would store this information in a chart, meaning it would not need to examine those words again on a subsequent pass, after backtracking.
· The initial chart for the sentence The cat eats a big fish is shown in Fig 10.3 It shows the chart that the chart parse algorithm would start with for parsing the sentence.
· The chart consists of seven vertices, which will become connected to each other by edges. The edges will show how the constituents of the sentence combine together.
· The chart parser starts by adding the following edge to the chart: [0, 0, Target→• Sentence]
· This notation means that the edge connects vertex 0 to itself (the first two numbers in the square brackets show which vertices the edge connects).
· Target is the target that we want to find, which is really just a placeholder to enable us to have an edge that requires us to find a whole sentence. The arrow indicates that in order to make what is on its left-hand side (Target) we need to find what is on its right-hand side (Sentence). The dot (•) shows what has been found already, on its left-hand side, and what is yet to be found, on its right-hand side. This is perhaps best explained by examining an example.
· Consider the following edge, which is shown in the chart in Figure 10.4: [0, 2, Sentence→NounPhrase • VerbPhrase]
· This means that an edge exists connecting nodes 0 and 2. The dot shows us that we have already found a NounPhrase (the cat) and that we are looking for a VerbPhrase.

· Once we have found the VerbPhrase, we will have what is on the left-hand side of the arrow—that is, a Sentence.
· The chart parser can add edges to the chart using the following three rules:
ü If we have an edge [x, y, A →B • C], which needs to find a C, then an edge can be added that supplies that C (i.e., the edge [x, y, C→ • E]), where E is some sequence of terminals or nonterminals which can be replaced by a C).
ü If we have two edges, [x, y, A →B • C D] and [y, z, C →E •}, then these two edges can be combined together to form a new edge:[x, z, A→B C • D].
ü If we have an edge [x, y, A →B • C], and the word at vertex y is of type C, then we have found a suitable word for this edge, and so we extend the edge along to the next vertex by adding the following edge: [y, y + 1, A→B C •].
Semantic Analysis
· Having determined the syntactic structure of a sentence, the next task of natural language processing is to determine the meaning of the sentence.
· Semantics is the study of the meaning of words, and semantic analysis is the analysis we use to extract meaning from utterances.
· Semantic analysis involves building up a representation of the objects and actions that a sentence is describing, including details provided by adjectives, adverbs, and prepositions. Hence, after analyzing the sentence The black cat sat on the mat, the system would use a semantic net such as the one shown in Figure 10.5 to represent the objects and the relationships between them.
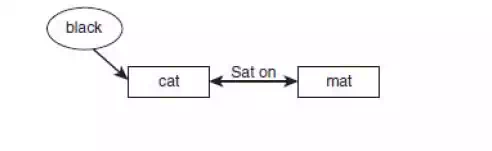
· A more sophisticated semantic network is likely to be formed, which includes information about the nature of a cat (a cat is an object, an animal, a quadruped, etc.) that can be used to deduce facts about the cat (e.g., that it likes to drink milk).
· Ambiguity and Pragmatic Analysis
· One of the main differences between natural languages and formal languages like C++ is that a sentence in a natural language can have more than one meaning. This is ambiguity—the fact that a sentence can be interpreted in different ways depending on who is speaking, the context in which it is spoken, and a number of other factors.
· The more common forms of ambiguity and look at ways in which a natural language processing system can make sensible decisions about how to disambiguate them.
· Lexical ambiguity occurs when a word has more than one possible meaning. For example, a bat can be a flying mammal or a piece of sporting equipment. The word set is an interesting example of this because it can be used as a verb, a noun, an adjective, or an adverb. Determining which part of speech is intended can often be achieved by a parser in cases where only one analysis is possible, but in other cases semantic disambiguation is needed to determine which meaning is intended.
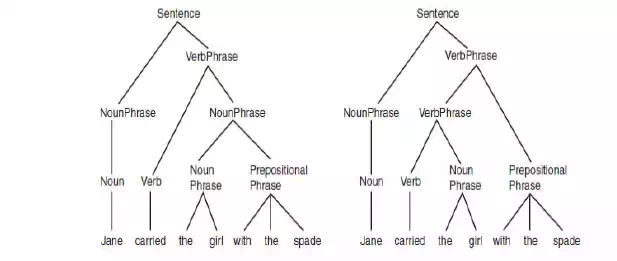
· Syntactic ambiguity occurs when there is more than one possible parse of a sentence. The sentence Jane carried the girl with the spade could be interpreted in two different ways, as is shown in the two parse trees in Fig 10.6. In the first of the two parse trees in Fig 10.6, the prepositional phrase with the spade is applied to the noun phrase the girl, indicating that it was the girl who had a spade that Jane carried. In the second sentence, the prepositional phrase has been attached to the verb phrase carried the girl, indicating that Jane somehow used the spade to carry the girl.
· Semantic ambiguity occurs when a sentence has more than one possible meaning—often as a result of a syntactic ambiguity. In the example shown in Fig 10.6 for example, the sentence Jane carried the girl with the spade, the sentence has two different parses, which correspond to two possible meanings for the sentence. The significance of this becomes clearer for practical systems if we imagine a robot that receives vocal instructions from a human.
· Referential ambiguity occurs when we use anaphoric expressions, or pronouns to refer to objects that have already been discussed. An anaphora occurs when a word or phrase is used to refer to something without naming it. The problem of ambiguity occurs where it is not immediately clear which object is being referred to. For example, consider the following sentences: John gave Bob the sandwich. He smiled.
· It is not at all clear from this who smiled—it could have been John or Bob. In general, English speakers or writers avoid constructions such as this to avoid humans becoming confused by the ambiguity. In spite of this, ambiguity can also occur in a similar way where a human would not have a problem, such as John gave the dog the sandwich. It wagged its tail.
· In this case, a human listener would know very well that it was the dog that wagged its tail, and not the sandwich. Without specific world knowledge, the natural language processing system might not find it so obvious.
· A local ambiguity occurs when a part of a sentence is ambiguous; however, when the whole sentence is examined, the ambiguity is resolved. For example, in the sentence There are longer rivers than the Thames, the phraselonger rivers is ambiguous until we read the rest of the sentence, than the Thames.
· Another cause of ambiguity in human language is vagueness. we examined fuzzy logic, words such as tall, high, and fast are vague and do not have precise numeric meanings.
· The process by which a natural language processing system determineswhich meaning is intended by an ambiguous utterance is known as disambiguation.
· Disambiguation can be done in a number of ways. One of the most effective ways to overcome many forms of ambiguity is to use probability.
· This can be done using prior probabilities or conditional probabilities. Priorprobability might be used to tell the system that the word bat nearly always means a piece of sporting equipment.
· Conditional probability would tell it that when the word bat is used by a sports fan, this is likely to be the case, but that when it is spoken by a naturalist it is more likely to be a winged mammal.
· Context is also an extremely important tool in disambiguation. Consider the following sentences:
ü I went into the cave. It was full of bats.
ü I looked in the locker. It was full of bats.
· In each case, the second sentence is the same, but the context provided by the first sentence helps us to choose the correct meaning of the word “bat” in each case.
· Disambiguation thus requires a good world model, which contains knowledge about the world that can be used to determine the most likely meaning of a given word or sentence. The world model would help the system to understand that the sentence Jane carried the girl with the spade is unlikely to mean that Jane used the spade to carry the girl because spades are usually used to carry smaller things than girls. The challenge, of course, is to encode this knowledge in a way that can be used effectively and efficiently by the system.
· The world model needs to be as broad as the sentences the system is likely to hear. For example, a natural language processing system devoted to answering sports questions might not need to know how to disambiguate the sporting bat from the winged mammal, but a system designed to answer any type of question would.