Molecular Level of Genetics
So far in this tutorial, chromosomes and genes have been described
broadly without saying precisely what they are composed of and how they
function. In order to better understand them, we need to look at the
molecular level of the cell.
Water is by far the most common type of molecule in the human body, normally amounting to 50-60% of our total adult weight. Most of the remaining molecules fall into one of four categories:
|
1. |
carbohydrates (sugars and starches) |
|
2. |
lipids (fats, oils, waxes, fatty acids, triglycerides and cholesterol) |
|
3. |
proteins |
|
4. |
nucleic acids |
Proteins are large chain-like molecules that are twisted and folded back on themselves in complex patterns. They serve as structural material for the body, gas transporters in blood, hormones , antibodies , neurotransmitters , and enzymes . When looking at someone, you mostly see proteins since skin, hair, and muscles are primarily made of them. Proteins acting as enzymes are particularly important substances because they trigger and control the chemical reactions by which carbohydrates, lipids, and other substances are created. Our human bodies produce about 90,000 different kinds of proteins, all of which consist of simpler units called amino acids . Proteins in all organisms are mostly composed of just 20 kinds of amino acids. Proteins differ in the number, sequence, and kinds of amino acids. Our bodies create some of these amino acids, while others come directly from food that we consume.
|
AMINO ACIDS |
|||
|
alanine |
glutamic acid |
leucine |
serine |
|
arginine |
glutamine |
lysine |
threonine |
|
asparagine |
glycine |
methionine |
tryptophan |
|
aspartic acid |
histidine |
phenylalanine |
tyrosine |
|
cysteine |
isoleucine |
proline |
valine |
|
(NOTE: The 8 amino acids in red cannot be synthesized
by the |
Proteins, and subsequently amino acids, are mostly made up of just four elements: carbon, oxygen, hydrogen, and nitrogen. In fact, 96.3% of a human body is composed of these common elements.
The largest molecules in people and other organisms are nucleic acids. Like proteins, they consist of very long chains of simpler units. However, the components, shapes, and functions of nucleic acids differ significantly from those of proteins. There are two basic forms of nucleic acids: DNA (deoxyribonucleic acid ) and RNA (ribonucleic acid ). Both play critical roles in the production of proteins. Some kinds of RNA perform other critical functions in our cells not related to protein synthesis.
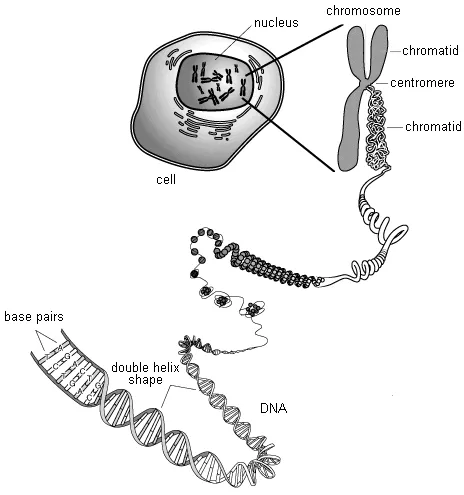
A chromosome consists mainly of a single very long DNA molecule and proteins called histones that densely package the DNA. There are many small RNA molecules surrounding the DNA as well. Each of our DNA molecules contains the genetic codes, or genes, for the synthesis of many different kinds of proteins and for the regulation of other genes. In a sense, a DNA molecule contains a sequence of permanently stored blueprints or recipes that are used mostly by our cells to assemble proteins out of amino acids. In other words, chromosomes are packets of information encoded by DNA. If all of the DNA molecules in a single human cell were straightened out and arranged end to end, it would form a thread about 6½ feet long but only a few atoms across. If the DNA in all of a normal adult human's cells were arranged in this way, the thread could reach the moon about 6,000 times.
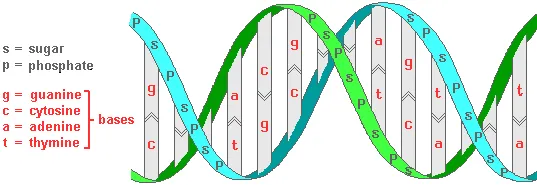
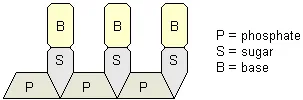
DNA molecules have the shape of a double helix , which is like a twisted ladder. The sides of the ladder are composed of sugar and phosphate units, while the rungs consist of complementary pairs of four different chemical bases. The base guanine only bonds to cytosine and adenine only bonds to thymine. Each combined sugar, phosphate, and base subunit is a nucleotide .
|
|
|
|
|
|
|
The linear sequence of base pairs along the length of a DNA molecule is the genetic code for the assembly of particular amino acids to make specific types of proteins. Therefore, a gene is essentially a recipe consisting of a sequence of some of these base pairs. The sequence is usually not continuous but is in several different sections of a DNA molecule. Sections of the same gene can be assembled in different ways resulting in recipes for different kinds of proteins. This "alternative splicing" process is common, occurring in 92-94% of human genes.
Only 1.1-1.5% of the approximately 3 billion base pairs in human DNA actually code for proteins. These meaningful code sequences are called exons . The remaining 98+% of our DNA base pairs were in the past thought to consist merely of genetic junk, including meaningless code section duplications and ancient remnants of parasitic DNA that invaded our ancestors' cells many millions of years ago. However, it is now becoming clear that much of this "junk" actually has important functions. These non-protein coding sections are referred to as introns . At least 80% of the intron regions of human DNA contain switches to turn the genes on and off. There are at least 4 million of these switches. Many of them are involved in monitoring and controlling cell functions throughout the body. Some also may be involved in a wide range of diseases including autoimmune responses (multiple sclerosis, lupis, rheumatoid arthritis, Crohn's disease, and celiac disease).
Textbooks written before 2001 most often stated that there are 100,000 human genes. This estimate was significantly reduced to about 30,000 as a result of completion of the initial phase of the Human Genome Project in that year. The number was further revised downward in 2004 by the National Human Genome Research Institute (NHGRI). It is now known that there are about 20,500 still functioning human protein-coding genes. Since the human genome "parts list" was compiled, research has largely focused on what these parts do--i.e., what proteins they code for and what those proteins do in our bodies. In addition, there is intense ongoing research to understand the short RNA molecules that are coded for by introns.
here is far more DNA variation between people than was thought possible in 2001 when the human genome was first worked out. The variations mostly show up in 1500 DNA regions (about 12% of the total). The differences are commonly in the form of deletions, duplications, and reversals of DNA segments and individual bases. Research is still at the beginning of the process of determining the significance of these differences. Understanding them very likely will shed considerable light on whether or not individuals might develop particular diseases. These variations are far more common and extensive than previously assumed. Current estimates are that 65-80% of people have copy number variants (CNV's) that are at least 100,000 base units long.
About half of the sequences of base units in human nuclear DNA are "mobile elements." They move around inserting new copies of themselves. When these insertions go into a gene, the result is a changed protein recipe. This is a major source of new genetic variation and potentially a cause of genetic diseases such as hemophilia and muscular dystrophy in families that did not previously have these defective genes.
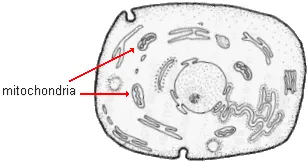
Not all of our DNA is in the cell nucleus. A small amount is in a circular looping chromosome in mitochondria --organelles located in the cytoplasm. Mitochondria use glucose, a sugar, derived from the food we eat to produce adenosine triphosphate (ATP). This is the fuel for many cell functions. Without ATP, cell activity would cease and we would die. There are about 500 mitochondria in each human cell. Muscle cells have more because they need additional ATP to function. The 16,569 base units of human mitochondrial DNA (mtDNA) have only 37 genes of which 13 code for proteins.
|
|
|
Generalized |
|
|
|
|
|
Sperm cell |
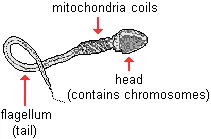
Unlike nuclear DNA (nDNA) in chromosomes, mtDNA is inherited almost exclusively from our mothers. In sperm cells, the mitochondria are located in coils between the flagellum tail and the head. They provide the fuel that allows sperm to move. It has been widely assumed that, at conception, the flagellum along with the mitochondria do not enter the ovum. We now know that this is not always true in the case of humans and other mammals. However, less than .1% of the mitochondrial DNA in a zygote normally comes from the father, and the genes in the paternal mtDNA apparently get turned off. Subsequently, for all intent purposes, we only inherit maternal mtDNA.
The second type of nucleic acid, RNA, consists of molecules that are single stranded copies of nuclear DNA segments. They are smaller than DNA molecules and do not have the double helix shape. In addition, the DNA base thymine is replaced by the base uracil in RNA molecules. The sugar component is also somewhat different. RNA is found in both the cell nucleus and the cytoplasm. The different kinds of RNA are described below.
Protein Synthesis
The genetic code is central to two critical functions within our cells. They are the creation of new proteins and the duplication of chromosomes during cell division. The former process is actually an assembly of existing amino acids in their proper sequences for each type of protein. Subsequently, it is referred to as protein synthesis rather than production. In this process, the recipe for a needed protein is first copied. Specifically, the relevant DNA code sequence is transcribed, or copied, to RNA. The process begins by a section of a DNA molecule unwinding and then unzipping in response to several interacting enzymes. The separation occurs between the bases, as shown below.
|
DNA molecule
partially |
|
|
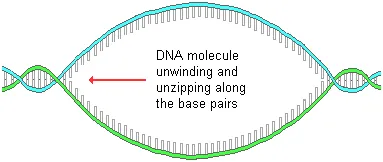
Free nucleotides in the nucleus are attracted to complimentary bases on the exposed DNA strands (guanine to cytosine and adenine to thymine). The result of this sequential bonding of base units is the formation of a messenger RNA (mRNA) molecule that is a copy, or transcription, of specific sections of the nuclear DNA molecule corresponding to a gene. Many identical copies are made, one right after another. In the process of mRNA formation, the non-coding sections are removed and the remaining exons are spliced together.
|
Free nucleotides
attracted |
|
|
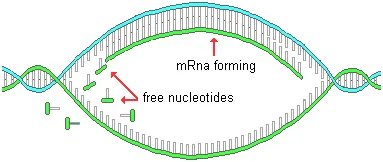
These new identical messenger RNA molecules then leave the nucleus and go out into the cytoplasm where the protein they are coded for is actually synthesized or assembled.
|
mRNA migrating out |
|
|
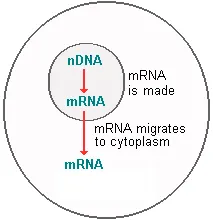
Specifically, the messenger RNA molecules migrate from the chromosomes to the ribosomes , which are small granule-like organelles in the cytoplasm. Some ribosomes are on the surface of long membrane networks called endoplasmic reticula , while others are free ribosomes. Assembly of proteins takes place at the site of the ribosomes.
|
Generalized animal cell |
|
|
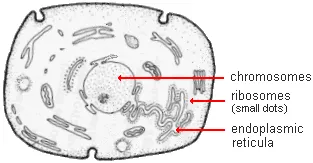
Protein synthesis begins as ribosomes move along the messenger RNA strand and attach transfer RNA (tRNA) anticodons (each with 3 bases) to triplets of complementary bases on the mRNA.
|
|
|
|
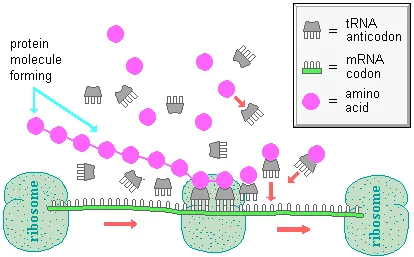
Each transfer RNA attracts and brings a specific amino acid along with it. As a ribosome translates (or activates) the messenger RNA code, a protein chain is assembled, one amino acid at a time. Each kind of amino acid has a particular codon that specifies it. A codon is a sequence of three nucleotide components chemically bound together (illustrated below). As mentioned earlier, every nucleotide consists of a sugar, a phosphate, and a base. Codons differ in terms of the sequence of their three bases. For example, the sequence CAG (cytosine-adenine-guanine) is a code for the amino acid glutamine.
|
|
|
|
This genetic code permits 64 different codons because each of the 3 nucleotides can have 1 of the 4 bases ( 4 X 4 X 4 = 64 ). Because there are many fewer than 64 amino acids, the code system has built in redundancy--most amino acids can be attracted by transfer RNA having several different base triplet combinations. In other words, some codons are functionally equivalent, as shown in the table below. For instance, asparagine is specified with the mRNA codon sequence AAU (adenine-adenine-uracil). However, AAC (adenine-adenine-cytosine) also works.
|
DNA AND RNA CODES FOR AMINO ACIDS |
||
|
Amino acids |
Corresponding DNA codons |
Corresponding RNA codons |
|
alanine |
CGA, CGG, CGT, CGC |
GCU, GCC, GCA, GCG |
|
arginine |
GCA, GCG, GCT, GCC, TCT, TCC |
CGU, CGC, CGA, CGG, AGA, AGG |
|
asparagine |
TTA, TTG |
AAU, AAC |
|
aspartic acid |
CTA, CTG |
GAU, GAC |
|
cysteine |
ACA, ACG |
UGU, UGC |
|
glutamic acid |
CTT,CTC |
GAA, GAG |
|
glutamine |
GTT, GTC |
CAA, CAG |
|
glycine |
CCA, CCG, CCT, CCC |
GGU, GGC, GGA, GGG |
|
histidine |
GTA, GTG |
CAU, CAC |
|
isoleucine |
TAA, TAG, TAT |
AUU, AUC, AUA |
|
leucine |
AAT, AAC, GAA, GAG, GAT, GAC |
UUA, UUG, CUU, CUC, CUA, CUG |
|
lysine |
TTT, TTC |
AAA, AAG |
|
methionine (start codon) |
TAC |
AUG |
|
phenylalanine |
AAA, AAG |
UUU, UUC |
|
proline |
GGA, GGG, GGT, GGC |
CCU, CCC, CCA, CCG |
|
serine |
AGA, AGG, AGT, AGC, TCA, TCG |
UCU, UCC, UCA, UCG, AGU, AGC |
|
threonine |
TGA, TGG, TGT, TGC |
ACU, ACC, ACA, ACG |
|
tryptophan |
ACC |
UGG |
|
tyrosine |
ATA, ATG |
UAU, UAC |
|
valine |
CAA, CAG, CAT, CAC |
GUU, GUC, GUA, GUG |
|
(stop codon) |
ATT, ATC, ACT |
UAA, UAG, UGA |
|
NOTE: the DNA base thymine (T) is replaced with uracil (U) in RNA. |
Not all codons specify amino acid components to be included in a protein. For instance, a start codon appears in DNA at the beginning of the code sequence for each gene and a stop codon is at the end. In other words, they indicate where a protein recipe begins and ends.
Most plant and animal cells, including those of humans, have thousands to millions of ribosomes. Many ribosomes simultaneously translate identical strands of messenger RNA. As a result, the synthesis of proteins can be rapid and massive. These same processes usually occur at the same time in millions of cells when a particular protein is needed. Inevitably, there are some errors in the code copying process. The result is mutations that cause the creation of incorrect proteins. However, there is an error checking and correction process carried out by enzymes that catches many of these errors. Recent research suggests that DNA to RNA copy mistakes are common.
Most of our genes code for several different proteins. This should not be surprising since we have only about a third as many genes as we do kinds of proteins. Some genes act in consort with other genes to produce the same protein. Some genes do not code for proteins at all. Recent research has shown that at least 200-255 of our genes code for micro RNA (miRNA) molecules instead. These are not messenger RNA's that transport the recipe for protein synthesis. Rather, they are small RNA molecules consisting of only around 20-25 base units. They perform important functions similar to enzymes in regulating chemical reactions in our cells, especially in the embryonic stage at the beginning of life. It is thought that at least 1/3 of human genes are controlled in some way by micro-RNA molecules.
DNA Replication
In addition to keeping the blueprints for protein synthesis, DNA has one further function. It replicates, or duplicates, itself. This occurs whenever a chromosome is duplicated for cell division. At the beginning of this process, the DNA molecule of a stretched out chromosome unwinds and unzips along its bases beginning at one end. Then in response to an enzyme, free nucleotides pair up with corresponding bases on both of the DNA strands, as illustrated below. This results in the formation of two exact copies of the original molecule. Nuclear DNA replication occurs in the rest period (interphase) just before mitosis and meiosis.
|
DNA |
|
|
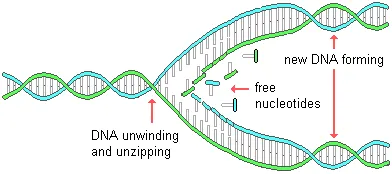
Occasionally, an error is made in DNA replication. For example, an incorrect base pair may be included. This constitutes a mutation. If it occurs in the formation of sex cells, the mutation may be inherited and passed on in future generations. Such errors are the principal source of new genetic variation for a species and, subsequently, play a major role in evolution. DNA replication errors are also responsible for changes in somatic cells that result in the uncontrolled tumor growths of cancers.
Universality of the Genetic Code
The DNA code system of humans is not unique but is shared by all living things on our planet. The same codons code for the same amino acids in people, dogs, fleas, and even bacteria. In addition, we share many genes with other creatures. For instance, about 90% of human genes are identical to those of a mouse. Even more surprising is the fact that more than 1/3 of our genes are shared with a primitive group of worm species known as nematodes. The universal nature of the genetic code is compelling evidence for the evolution of all organisms from the same early life forms.
Epigenome
Whether a gene is copied for protein synthesis and what the product of that copy becomes is largely determined by signals from proteins acting as markers and switches along the DNA double helix structure. This chemical signaling system, referred to as the epigenome, is very likely as important as the DNA itself in determining the phenotype of individuals. It is becoming increasingly clear that epigenetic signals can be altered by the environment. This partly explains why monozygotic twins progressively become different from one another as they grow older despite the fact that they are genetically identical.
Epigenetic changes can be passed on to future generations because epigenome proteins are inherited along with DNA in chromosomes from parents. Unlike mutations in DNA sequences, however, epigenetic alterations potentially can be reversible. For example, if a change in an epigenetic protein causes a disease, it could be possible to alter that protein and bring about a cure. As a consequence, learning more about the human epigenome is likely to be an important area for future medical research.
Epigenome
Whether a gene is copied for protein synthesis and what the product of that copy becomes is largely determined by signals from proteins acting as markers and switches along the DNA double helix structure. This chemical signaling system, referred to as the epigenome, is very likely as important as the DNA itself in determining the phenotype of individuals. It is becoming increasingly clear that epigenetic signals can be altered by the environment. This partly explains why monozygotic twins progressively become different from one another as they grow older despite the fact that they are genetically identical.
Epigenetic changes can be passed on to future generations because epigenome proteins are inherited along with DNA in chromosomes from parents. Unlike mutations in DNA sequences, however, epigenetic alterations potentially can be reversible. For example, if a change in an epigenetic protein causes a disease, it could be possible to alter that protein and bring about a cure. As a consequence, learning more about the human epigenome is likely to be an important area for future medical research.