Risk and failure in complex engineering systems
“We must ensure this never happens again.”
This is a common reaction to instances of catastrophic failure. However,
in complex engineering systems, this statement is inherently paradoxical. If
the right lessons are learned and the appropriate measures are taken, the same
failure will most likely never happen again. But, catastrophes in themselves
are not completely preventable, such that the next time around, failure will
occur somewhere new and unforeseen. Welcome to the world of complexity.
Boiled down to its fundamentals, engineering deals with the practical –
the development of tools that work as intended. Failure is a human condition,
and as such, all man-made systems are prone to failure. Furthermore, success
should not be defined as the absence of failure, but rather how we cope with
failure and learn from it – how we conduct ourselves in spite of failure.
Failure and risk are closely linked. The way I define risk here is the
probability of an irreversible negative outcome. In a perfect world of complete
knowledge and no risk, we know exactly how a system will behave beforehand and
have perfect control of all outcomes. Hence, in such an idealised world there
is very little room for failure. In the real world however, knowledge is far
from complete, people and man-made systems behave and interact in unforeseen
ways, and changes in the surrounding environmental conditions can drastically
alter the intended behaviour. Therefore, our understanding of and attitude
towards risk, plays a major role in building safe engineering systems.
The first step is to acknowledge that our perception of risk is very
personal. It is largely driven by human psychology and depends on a favourable
balance of risk and reward. For example, there is a considerable higher degree
of fear of flying than fear of driving, even though air travel is much safer
than road travel. As plane crashes are typically more severe than car crashes,
it is easy to form skewed perceptions of the respective risks involved. What is
more, driving a car, for most people a daily activity, is far more familiar
than flying an airplane.
Second, science and engineering do not attempt to predict or guarantee a
certain future. There will never be a completely stable, risk free system. All
we can hope to achieve is a level of risk that is comparable to that of events
beyond our control. Risk and uncertainty arise in the gap between what we know
and what we don’t – between how we design the system to behave and how it can
potentially behave. This knowledge gap can lead to two types of risk. There are
certain things we appreciate that we do not understand, i.e. the known
unknowns. Second, and more pernicious, are those things we are not even aware
of, i.e. the unknown unknowns, and it is these failures that wreak the most
havoc. So how do we protect ourselves against something we don’t even see
coming? How do engineers deal with this second type of risk?
The first strategy is the safety factor or margin of safety. A safety
factor of 2 means that if a bridge is expected to take a maximum service load
of X (also called the demand), then we design the structure to hold 2X (also
called the capacity). In the aerospace industry, safety protocols require all
parts to maintain integrity up to 1.2x the service load, i.e. a limit safety
factor of 1.2. Furthermore, components need to sustain 1.5x the service load
for at least three seconds, the so-called ultimate safety factor. In some
cases, statistical techniques such as Monte Carlo analyses are used to
calculate the probability that the demand will exceed the capacity.
The second strategy is to employ redundancies in the design. Hence,
back-ups or contingencies are in place to prevent a failure from progressing to
catastrophic levels. In structural design, for example, this means that there
is enough untapped capacity within the structure, such that a local failure
leads to a rebalancing/redirection of internal loads without inducing
catastrophic failure. Part of this analysis includes the use of event and fault
trees that require engineers to conjure the myriad of ways in which a system
may fail, assign probabilities to these events, and then try to ascertain how a
particular failure affects other parts of the system.
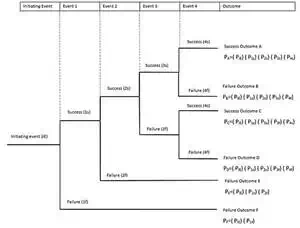
Even tree diagram (via Wikimedia Commons).
Unfortunately, some engineering systems today have become so complex
that it is difficult to employ fault and event trees reliably. Rising
complexity means that is impossible to know all functional interactions
beforehand, and it is therefore difficult, if not impossible, to predict
exactly how failure in one part of the system will affect other parts. This phenomenon
has been popularised by the “butterfly effect” – a scenario in which, in an
all-connected world, the stroke of a butterfly’s wings on one side of the
planet, causes an earthquake on the other.
The increasing complexity in engineering systems is driven largely by
the advance of technology based on our scientific understanding of physical
phenomena at increasingly smaller length scales. For example, as you are
reading this on your computer or smartphone screen, you are, in fact,
interacting with a complex system that spans many different layers. In very
crude terms, your internet browser sits on top of an operating system, which is
programmed in one or many different programming languages, and these languages
have to be translated to machine code to interact with the microprocessor. In
turn, the computer’s processor interacts with other parts of the hardware such
as the keyboard, mouse, disc drives, power supply, etc. which have to interface
seamlessly for you to be able to make sense of what appears on screen. Next,
the computer’s microprocessor is made up of a number of integrated circuits,
which are comprised of registers and memory cells, which are further built-up
from a network of logic gates, which ultimately, are nothing but a layer of
interconnected semiconductors. Today, the expertise required to handle the
details at a specific level is so vast, that very few people understand how the
system works at all levels.
In the world of aviation, the Wright brothers were the first to realise
that no one would ever design an effective aircraft without an understanding of
the fields of propulsion, lift and control. Not only did they understand the
physics behind flight, Orville and Wilbur were master craftsmen from years of
running their own bike shop, and later went as far as building the engine for
the Wright Flyer themselves. Today’s airplanes are of course significantly more
sophisticated than the aircraft 100 years ago, such that in-depth knowledge of
every aspect of a modern jumbo jet is out of the question. Yet, the risk of
increasing specialism is that there are fewer people that understand the
complete picture, and appreciate the complex interactions that can emerge from
even simple, yet highly interconnected processes.
With increasing complexity, the solution should not be further
specialisation and siloing of information,
as this increases the potential for unknown risks. For example, consider the
relatively simple case of a double pendulum. Such a system is described by
chaotic behaviour, that is, we know and understand the underlying physics of
the problem, yet it is impossible to predict how the pendulum will swing a
priori. This is because at specific points, the system can bifurcate into a
number of different paths, and the exact behaviour depends on the nature of the
initial conditions when the system is started. These bifurcations can be very
sensitive to small differences in the initial conditions, such that two
processes that start with almost the same, but not identical, initial conditions
can diverge considerably after only a short time.

A double rod pendulum animation showing chaotic behaviour
(via Wikimedia Commons).
Under these circumstances, even small local failures within a complex
system can cascade rapidly, accumulate and cause global failure in unexpected
ways. Thus, the challenge in designing robust systems arises from the fact that
the performance of the complete system cannot be predicted by an isolated
analysis of its constituent parts by specialists. Rather, effective and safe
design requires holistic systems thinking. A key aspect of systems thinking is
to acknowledge that the characteristics of a specific layer emerges from
the interacting behaviour of the components working at the level below. Hence,
even when the behaviour of a specific layer is governed by understood
deterministic laws, the outcome of these laws cannot be predicted with
certainty beforehand.
In this realm, engineers can learn from some of the strategies employed
in medicine. Oftentimes, the origin, nature and cure of a disease is not clear
beforehand, as the human body is its own example of a complex system with
interacting levels of cells, proteins, molecules, etc. Some known cures work
even though we do not understand the underlying mechanism, and some cures are
not effective even though we understand the underlying mechanism. Thus, the
engineering design process shifts from well-defined rules of best practise
(know first then act) to emergent (act first then know), i.e. a system is
designed to the best of current knowledge and then continuously
iterated/refined based on reactions to failure.
In this world, the role of effective feedback systems is critical, as
flaws in the design can remain dormant for many years and emerge suddenly when
the right set of external circumstances arise. As an example, David Blockley provides an interesting analogy of how
failures incubate in his book “Engineering: A very short introduction.”
“…[Imagine] an inflated balloon
where the pressure of the air in the balloon represents the ‘proneness to
failure’ of a system. … [W]hen air is first blown into the balloon…the first
preconditions for [an] accident are established. The balloon grows in size and
so does the ‘proneness to failure’ as unfortunate events…accumulate. If [these]
are noticed, then the size of the balloon can be reduced by letting air out –
in other words, [we] reduce some of the predisposing events and reduce the
‘proneness to failure’. However, if they go unnoticed…, then the pressure of
events builds up until the balloon is very stretched indeed. At this point,
only a small trigger event, such as a pin or lighted match, is needed to
release the energy pent up in the system.”
Often, this final trigger is blamed as the cause of the accident. But it
isn’t. If we prick the balloon before blowing it up, it will subsequently leak
and not burst. The over-stretched balloon itself is the reason why an accident
can happen in the first place. Thus, in order to reduce the likelihood of
failure, the accumulation of preconditions has to be monitored closely, and
necessary actions proposed to manage the problem.
The main challenge for engineers in the 21st century is not more
specialisation, but the integration of design teams from multiple levels to
facilitate multi-disciplinary thinking across different functional boundaries.
Perhaps, the most important lesson is that it will never be possible to ensure
that failures do not occur. We cannot completely eliminate risk, but we can
learn valuable lessons from failures and continuously improve engineering
systems and design processes to ensure that the risks are acceptable.